

When the National Security Agency (NSA) in the U.S. released the Accumulo project into open source territory in 2008, there were not a lot of details about the size and capability of the hardware it was running, although it is safe to say that the NSA found ways to make it scale across some of their larger machines. However, as one might imagine, scale alone did not define a successful NSA database system—the security also had to be robust and guaranteed.
Even still, it is the security features of Accumulo that tend to draw the most attention, especially since there are other NoSQL database approaches that provide roughly the same outcome (HBase, for instance). Combined with massive scalability and this feature, it is not difficult to see how Accumulo still stands to thrive in the enterprise, particularly with supported version from defense and government-focused companies like Sqrrl.
Since the time of its NSA release, the Apache Foundation has managed the Accumulo codebase through its rise in popularity against other NoSQL options. The distributed key-value store approach that is central to its scalability is based on Google’s BigTable, which sits above Hadoop, Zookeeper, and Thrift, all of which are also Apache projects. The Java-based Accumolo, despite adoption in enterprise and web-scale datacenters, is rare to hear of inside supercomputing centers. But a team from MIT is dusting it off and finding ways to tap into the large amounts of compute power on HPC systems for high performance Accumulo operations.
MIT’s Lincoln Laboratory has been a prime center for work on Accumulo, with much of the published research coming from there, including key papers introducing Accumulo for widespread use in 2012 and another important work that put forth the D4M 2.0 schema to lend high performance to the framework. Most recently, the MIT teams have set to work developing a vision for Accumulo to run on HPC clusters, or supercomputers, with help from old toolsets like the Grid Engine scheduling resource and newer data ecosystem tools like Zookeeper.
The net product of the work with Accumulo, along with other databases appropriate for use in HPC circles like SciDB, is called the MIT SuperCloud database management system. The goal is to make it simple for users with traditional HPC applications to be able to use these data-intensive computing tools in much the same way as with their usual scientific applications. As the researchers describe, the SuperCloud database management system ensures “the seamless migration of the databases to the resources assigned by the HPC scheduler [in this case Grid Engine] and centralized storage of the database files when not running.” The system also allows for other standard features, including snapshotting.
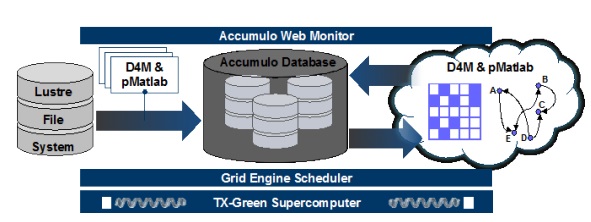 As shown on the right, there are other recognizable features more likely to be found on supercomputers rather than enterprise systems, including the Lustre file system. All of this runs on the TX-Green supercomputer, which is a 270 node HP machine hooked via a single 10GbE Arista core switch. The Lustre file system uses a petabyte array from DataDirect Networks, creating a system that has over 8600 cores, 128 GB memory, and a collective 12 TB of storage. The MIT SuperCloud stack sits on each individual node as that accelerates the launch of large applications (like databases) while limiting the draw of these on the central storage system.
As shown on the right, there are other recognizable features more likely to be found on supercomputers rather than enterprise systems, including the Lustre file system. All of this runs on the TX-Green supercomputer, which is a 270 node HP machine hooked via a single 10GbE Arista core switch. The Lustre file system uses a petabyte array from DataDirect Networks, creating a system that has over 8600 cores, 128 GB memory, and a collective 12 TB of storage. The MIT SuperCloud stack sits on each individual node as that accelerates the launch of large applications (like databases) while limiting the draw of these on the central storage system.
While there are far more details here, including benchmarks showing both performance and scalability, the team was able to demonstrate how the SuperCloud database management system can allow for quick spin-ups of a variety of databases, particularly Accumulo.
The team concludes that they have allowed for database jobs to run on HPC systems as seamlessly as other supercomputing jobs by de-coupling the databases from concrete hardware and optimizing how the hardware is used (i.e. by stopping databases that aren’t in use and restarting them quickly on whatever hardware is available). In the end, this “significantly lowers the barriers to using this advanced technology” and likely sets the stage for future work using Accumulo in ultra-high performance environments, especially given its attractive emphasis on strict security.


The Supercomputing Efficiency Curve Bends In The Right Direction
Things get a little wonky at exascale and hyperscale. Things that don’t matter quite as much at enterprise scale, such as the cost or the performance per watt or the performance per dollar per watt for a system or a cluster, end up dominating the buying decisions. The main reason …

Wanted: An Energy-Aware Datacenter Application Scheduler
Around the world, the number and size of datacenters are both growing at a fast pace, and the devices housed in them are consuming more and more power as well to deliver ever-increasing performance. And as a consequence, datacenters are using more and more of the planet’s energy to do …

For Future Systems, Coordination is the Next Big Bottleneck
For last several decades, large-scale computing, whether for massive supercomputers or distributed enterprise systems, has been engaged in a never-ending game of whack-a-mole. Less colloquially, of chasing down one bottleneck bubble, only to find it revived elsewhere in the system with equal force. That endless game is still being played, …
Be the first to comment