

One look at the IBM technology roadmap reveals that future emphasis, particularly on the software and applications side, will revolve around that catch-all trend that couples various elements from speech, text, and image recognition to create a brain-like system with reasoning and judgment capabilities–not to mention near-instant access to the world’s information.
This movement is, of course, collectively referred to as cognitive computing and the capabilities collected under the broad application umbrella are finding a way into more enterprise environments, most notably in healthcare. The Watson division at IBM, which is pushing the evolution of smart machines and software through new algorithmic advancements, sees the path clearly in terms of the value these systems will provide–but pushing systems to evolve, especially algorithmically, is proving to be quite a challenge. Interestingly, the real problems companies like IBM face have less to do with hard technology limits and are more centered around next-generation development challenges on platforms that are evolving greatly—and at a rate that development cycles are struggling to keep pace with.
“The non-messy way to develop would be to create one big knowledge model, as with the semantic web, and have a neat way to query it. But that would not be flexible enough and not provide enough coverage. So we’re left with the messy way. Instead of taking data and structuring it in one place, it’s a matter of keeping data sources as they are—there is no silver bullet algorithm to use in this case either. All has to be combined, from natural language processing, machine learning, knowledge representation. And then meshed as some kind of distributed infrastructure.”
“When it comes to neural networks, we don’t entirely know how they work,” explains Jerome Pesenti, vice president of the Watson team at IBM. “And what’s amazing is that we’re starting to build systems we can’t fully understand. The math and the behavior are becoming very complex and my suspicion is that as we create these networks that are ever larger and keep throwing computing power to it, which creates some interesting methodological problems.”
So how does a company, even the size of Big Blue, go about pushing the next generation of cognitive applications if the system and software evolution are outpacing normal approaches to development?
There are two approaches that IBM was left to decide between with its cognitive software development projects, including those that back a wide range of enterprise segments. “They put everyone in a room before the Jeopardy experiments,” for instance, Pesenti says. “That yielded 8,000 experiments over four years. Less than 20 percent made it.”
Pesenti says this is for a range of reasons, from testing in isolation, playing around with algorithmic interactions, gauging progress with fuzzy outputs, and of course, testing for bugs in code that was beginning to take on a life of its own. This is where the real problem lies with the future of cognitive computing—at some point, the development will have to meet the algorithmic complexity of the design, which means the only approach left is the “messy” one.
“The non-messy way to develop would be to create one big knowledge model, as with the semantic web, and have a neat way to query it,” Pesenti tells The Next Platform. “But that would not be flexible enough and not provide enough coverage. So we’re left with the messy way. Instead of taking data and structuring it in one place, it’s a matter of keeping data sources as they are—there is no silver bullet algorithm to use in this case either. All has to be combined, from natural language processing, machine learning, knowledge representation. And then meshed as some kind of distributed infrastructure.”
What IBM ended up as a result of the iterative — and to some degree, failure-based — approach to melding multiple algorithms, application areas, and knowledge sets looks something like what Pesenti shares below, but this distributed architecture will need to continue to expand for domain-specific needs, not to mention for further development of cognitive capabilities inside IBM’s Watson research groups.
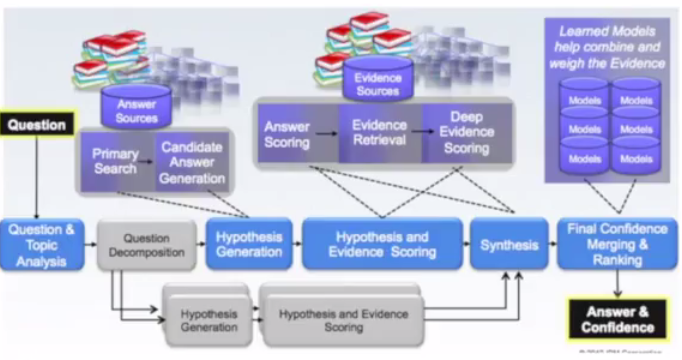
Pesenti has encountered the unknown with development cycles before, including most famously with the development of novel search engine (for the time) technology through the startup Vivisimo, which was spun out of work at Carnegie Mellon University. The startups Velocity search functionality was the backend for a number of federal projects in the U.S. and served as the enterprise search backbone for a number of large companies. IBM bought the company in 2012 to add to their big data portfolio before packaging up the technology to move into the Watson group’s circles shortly thereafter. He notes that the “test all” approach could not have worked with a smaller team—it takes the massive, combined effort of many researchers with the freedom to test and fail. And that has to be tough news for startup companies trying to put together comprehensive systems that can achieve sufficient algorithmic and source complexity to thrive.
Beyond remarking on the unsettling fact that there is an unaided growth of cognitive capabilities, pushed forth by ever-more exact feature recognition and linking, the question becomes how cognitive computing will progress if the software development is outpaced by the intelligence of the systems. While Pesenti does not see this as a problem yet, per se, it has already created research and development chasms that are causing the Watson teams to think about how they will develop the next generation of cognitive applications. And from a methodology problem perspective, teams inside the Watson group are heading back to the “throw it all against a wall to see what sticks” paradigm. This means a lot of failure, a lot of “wasted” research, but ultimately, the small percentage of successes make it worthwhile from an IBM R&D investment point of view.
While a company like IBM, particularly in its research division, can put together large groups of bright minds and throw away up to 80 percent of what rolls out that think factory, spurring this kind of development (which is based on failure, testing, and more failure before a product can rear its head) is not realistic for many companies. And further, says Pesenti, the challenge is seeing the bigger picture within those tests and failures—with so many moving parts, what appears to be a success might not, in practice, be useful at all.
The big issue with the Watson development cycle too is that teams are not just solving problems for one particular area. Rather, they have to create generalizable applications, which means what might be good for healthcare, for instance, might not be a good fit—and in fact even be damaging to—an area like financial services. The push and pull and tradeoff of the development cycle is therefore always hindered by this—and is the key barrier for companies any smaller than an IBM, Google, Microsoft, and other giants.


IBM Mashes Up PowerAI And Watson Machine Learning Stacks
Earlier in this decade, when the hyperscalers and the academics that run with them were building machine learning frameworks to transpose all kinds of data from one format to another – speech to text, text to speech, image to text, video to text, and so on – they were doing …

Put Building Data Culture Ahead Of Buying Data Analytics
In his keynote at the recent AWS re:Invent conference, Amazon vice president and chief technology officer Werner Vogels said that the cloud had created a “egalitarian” computing environment where everyone has access to the same compute, storage, and analytics, and that the real differentiator for enterprises will be the data …
Easing The Pain Of Prepping Data For AI
Organizations are turning to artificial intelligence and deep learning in hopes of being able to more quickly make the right business decisions, to remake their business models and become more efficient, and to improve the experience of their customers. The fast-emerging technologies will let enterprises gain more insight into the …
The attention on challenges in scaling system that can benefit from large amount of background/domain knowledge is important. And I also agree that neat, well crafted, traditionally built software systems would not be efficient. But, I can’t get myself to agree with some statements such as these: “The non-messy way to develop would be to create one big knowledge model, as with the semantic web, and have a neat way to query it.” That is an inaccurate way to characterise Semantic Web. Semantic Web (approach) is not all about building one consistent, comprehensive ontology to build one solution. DBPedia or Freebase cover a lot of domains, and linked open data consists of a large number of independently created, at times of indifferent quality, and at times inconsistent knowledge clusters. Black box approaches (aka ML incl neural networks) is not the only way to scale. White box approaches are possible and have benefits (they can explain the reasoning and outcomes, and often that is critical).
This statement is completely consistent with the Semantic Web approach (it seems to be implied that it is not): “All has to be combined, from natural language processing, machine learning, knowledge representation. ” Semantic (web) computing (and its use of background/domain knowledge) routinely enhances NLP and ML. The “instead of (semantic web)” implied in this paragraph is misplaced. This is just as misplaced as an assertion in 2005 that ontologies and semantic technologies can’t help in search- well we know in 2013, Google figured out using “knowledge graph” (a knowledge first hand built -Freebase- and then built by semiautomatic and automatic means) [for more on this. see [1]) to come out with semantic search (some historical notes in [2], if interested on this topic).
An important hypothesis this article makes is: “software development is outpaced by the intelligence of the systems.” If the system is becoming more intelligent, while we are benefiting from more powerful algorithms (e.g., recent progress in scaling deep learning and its applications), equally or even more important is out ability to use a system that has a variety of methods/algorithms/reasoning and then our ability to pick the right ones to solve a problem. It seems that is what Watson is about– ability to synthesize a broader variety of computational methods to solve a problem– just as what our brain seems to be able to with its top brain and bottom brain working together.
[1] http://amitsheth.blogspot.com/2007/05/semantic-web-different-perspective-on.html
[2] http://amitsheth.blogspot.com/2014/09/15-years-of-semantic-search-and.htmlless
>“When it comes to neural networks, we don’t entirely know how they work,”
That’s very annoying – we know exactly how they work, one just can’t always immediately comprehend the complex emergent behavior they exhibit as a system. (But I guess it’s better press to act surprised by the supposed intelligence of your golden step-child than not.)
As for the “messy way” – that’s the way it should be done, by the consuming/interpreting agent acquiring the knowledge so that it can actually be used effectively – there can’t be “one big knowledge model” divorced from a rational agent, or it’s not *knowledge*, it’s *data*.
So the Semantic Web is still data, albeit in a more consumable form for semantically-leaning software than it had been made available previously – but most of the benefit of the SW isn’t the fact that it’s made of RDF triples or any other specific AI-friendly technology – it’s that the data is actually there where there had been a void previously.
Imagine this technology applied in military branch ! And even in the business sector !
That there will be impacts on society?
The machines should have so much power ?
Has anyone wondered about this?
I think this technology, must be controlled !