

Before leaving Google in 2013, Felix Hupfeld and Bjorn Kolbeck took careful note of the seamless way the search giant’s storage systems operated almost automatically, with tiny teams operating the storage backbone that powered hundreds of thousands of servers in the United States and Europe.
Google’s advanced storage systems were obviously a far cry from the open source grid computing file system they worked on together at a supercomputing center in Germany in their pre-Google days, called XtreemFS, but the duo started to see how a flexible file system framework could be decoupled from big pools of commodity hardware and automated to handle failures, inflexibility, and data protection in one package.
While they were forced to move away from further development on XtreemFS to tackle the exabyte-class storage challenges at Google centers in New York and Zurich, a few particularly clever elements of the research file system stuck with them, most notably, the file system’s ability to tap high-latency links for large-scale distributed research projects in Europe. When they founded Quobyte, which has split offices between Boston and Germany, the goal was to move lessons from grid computing into the software-based automation that makes Google’s datacenters operate so efficiently. In essence, the two took the best form XtreemFS, rewrote the base from scratch, and added elements to extend beyond distributed HPC research in academia into the enterprise, separating the storage system from the hardware in a layer that still allow for the operation of Hadoop clusters, virtual machines and other environments.
As Kolbeck recalled during a conversation with The Next Platform, “If you look at the Google file system, it’s specially designed for their applications and is extraordinarily efficient with only a few people operating the storage for the different times zones. They can do that because the storage is decoupled from the hardware, which means the people that run the storage systems don’t ever have to interact with the hardware people about maintenance, preparing individual drives, and so on unless there is a really big problem.”
The goal then, as gathered from the Google exabyte-level automated storage systems is that the software should be able to seamlessly handle outages—and at that scale, outages are the norm, not the exception. While this might not be the case for the mid-sized HPC and enterprise datacenters where the pair’s startup, Quobyte, has found some users, the fault tolerant design and hardware decoupling are still useful, especially when paired with some key data integrity and protection features other high performance file system and storage appliance approaches are missing, says Kolbeck.
Quobyte was developed with the open source XtreemFS base in mind architecturally, so underneath, it’s essentially a parallel file system, but one that goes beyond others in HPC in particular. “We tend to leave Lustre out when we think about comparing Quobyte because it has a mixed track record with data safety. It is very fast, very high performance, but it’s not used if it’s data you want to keep for an extended time. While Lustre is great for scratch, what we’re really targeting are users with GPFS or a SAN appliance.” The goal of enabling parallel throughput plus data protection is important, which is why Kolbeck says they’ve added advanced replication and with the newest version, erasure coding. “We don’t apply redundant hardware like Lustre does and we don’t require a RAID controller. So when a drive or node fails, there can be quick restoration across any available resource in the storage clusters automatically.” He says that people are looking for alternatives to GPFS in particular in both enterprise and HPC and the fact that there is more flexibility built into Quobyte (for instance, there is no need to define block files up front and allows flexible block sizes at the file level, can allow an arbitrary number of file systems with thin provisioning, and interestingly, permits rapid scaling starting with four nodes and snapping in more to move with demand.
It might be freeing to think of Quobyte as not just a single file system since it can do double (or quadruple) duty by maintaining files in volumes, which are namespaces governed by user-defined parameters and policies that are then managed with quotes. This means uses can partition their installations. As Kolbeck describes, the scalability comes with the tiered architecture to manage the volumes as shown below.
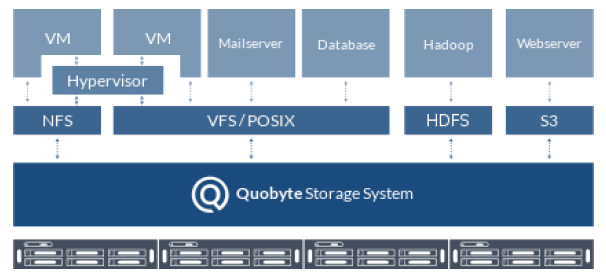
To put Quobyte into this perspective, the team has built their own drivers that hook into HDFS. One feature that early users of XtreemFS might remember that set it apart was the ability for users to control data placement. This is an attractive feature for existing users of Ceph, who need a capability that addresses metadata and using policies and other information, can provide the best placement of data stored for Hadoop workloads.
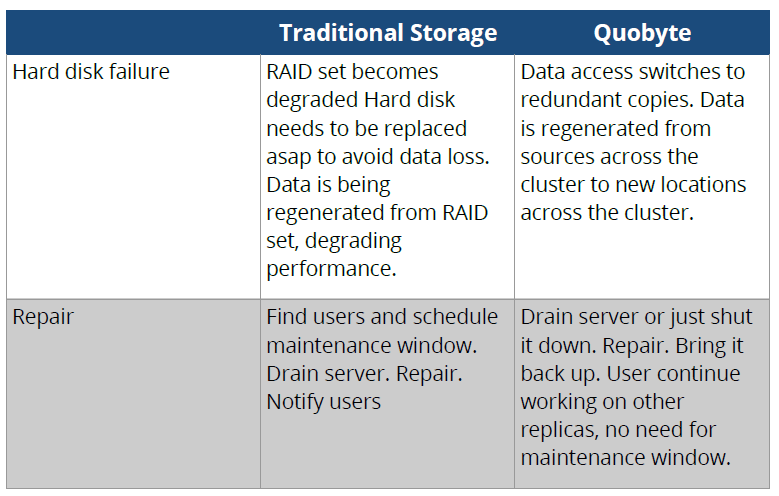
The fault tolerance side to the Quobyte story is one that Kolbeck thinks will resonate with HPC and enterprise users alike since this is a weak point in some existing solutions.This is where the Google style automation comes into play. Kolbeck and his partner were fascinated with the efficient routes the Google software took to route around failures and implemented an end-to-end checksum protection architecture, which he says can detect and repair corrupted data automatically. Of course, not all failures are so cut and dry. “When networks fail, for instance, the system can be split into several parts that continue to operate, but mutually think the other part has failed.” He says problems like this can be addressed in that partitioned way that defines the rest of their approach—fully automated and split across the cluster.
 The point is being able to provide all of this in a way that can be managed by a very small team while still having the option for rapid scalability. In addition to targeting HPC centers, Kolbeck says that they’ve tuned Quobyte to meet the demands of enterprise databases and virtual machines as well as Hadoop and Spark workloads. “From our perspective, those are very similar to HPC on the storage side. Enterprise users want storage systems that can serve all these areas. We are seeing a convergence of enterprise and HPC workloads and want to make sure all of these can be managed with one system without throwing another silo on top of the existing infrastructure.” Accordingly, they have created their system so users can run their virtual machines, database applications, and Hadoop all on the same cluster, accessing the same pool instead of, for example, breaking the Hadoop piece out, which is more likely to sit underutilized, especially since that storage would otherwise only be available to Hadoop, which means a lot of drives sitting idle.
The point is being able to provide all of this in a way that can be managed by a very small team while still having the option for rapid scalability. In addition to targeting HPC centers, Kolbeck says that they’ve tuned Quobyte to meet the demands of enterprise databases and virtual machines as well as Hadoop and Spark workloads. “From our perspective, those are very similar to HPC on the storage side. Enterprise users want storage systems that can serve all these areas. We are seeing a convergence of enterprise and HPC workloads and want to make sure all of these can be managed with one system without throwing another silo on top of the existing infrastructure.” Accordingly, they have created their system so users can run their virtual machines, database applications, and Hadoop all on the same cluster, accessing the same pool instead of, for example, breaking the Hadoop piece out, which is more likely to sit underutilized, especially since that storage would otherwise only be available to Hadoop, which means a lot of drives sitting idle.

Be the first to comment