

Anyone who has worked on the Google File System and then founded a hyperconverged server-storage company is probably going to have a slightly different perspective on all of the secondary storage in the datacenter that is used to house everything but the mission critical data that ends up on so-called “tier one” storage.
Having worked on addressing tier one storage needs in the modern datacenter through the founding of Nutanix, and seen the inner workings of storage at the search engine giant, Mohit Aron is taking a stab at reducing the complexity in the racks of hardware that are used for archiving, backups, and analytics datastores.
Aron got his big break in the hyperscale arena as a staff engineer working on the Google File System for nearly five years in the early-to-mid 2000s, and the smallest GFS clusters at the time, Aron explains to The Next Platform, had 10,000 nodes in them. “If GFS got much smaller than that, my team was not interested in debugging it,” Aron quips. From there, Aron moved on to become the architect at parallel database maker Aster Data Systems, which was acquired by Teradata for $263 million four years ago. Aron was one of the co-founders of hyperconverged appliance pioneer Nutanix, which was established in 2009 and uncloaked from stealth mode in 2011. Aron left Nutanix in 2013, but still has shares in the company and says he is quite pleased with the uptake of hyperconverged systems and how well Nutanix is doing in the market it helped create. But even with that success, Aron says he wanted to tackle a different problem.
At his latest startup, called Cohesity, which has just uncloaked from stealth and which has raked in $70 million in two rounds of funding, Aron is focusing not on the tier one storage that feed transaction processing and other mission critical applications, but all of the other storage that is used down in the second tier. And perhaps more importantly, the new distributed object file system that Cohesity has come up with has a more sophisticated form of snapshotting that will make it far easier for IT shops to manage their development, test, and production environments.
“No matter where you look in the secondary storage space, you see problems,” says Aron. “Some companies have ten different vendors. The world spends tens of billions of dollars on data protection, and doesn’t use it in the common case. It is just sitting there, as an insurance policy, eating dust. To use that data, we have to move it to a test/development environment or an analytics environment. Moreover, when you move data from production to analytics or test/dev, there is a delay. You see fragmentation of products, you see inefficiency, you see lots of copies, you see data movement, you see lack of scale-out, you see customers buying lots of licenses to a lot of different software. It is just a mess, and that is why we think secondary storage is ripe for disruption.”
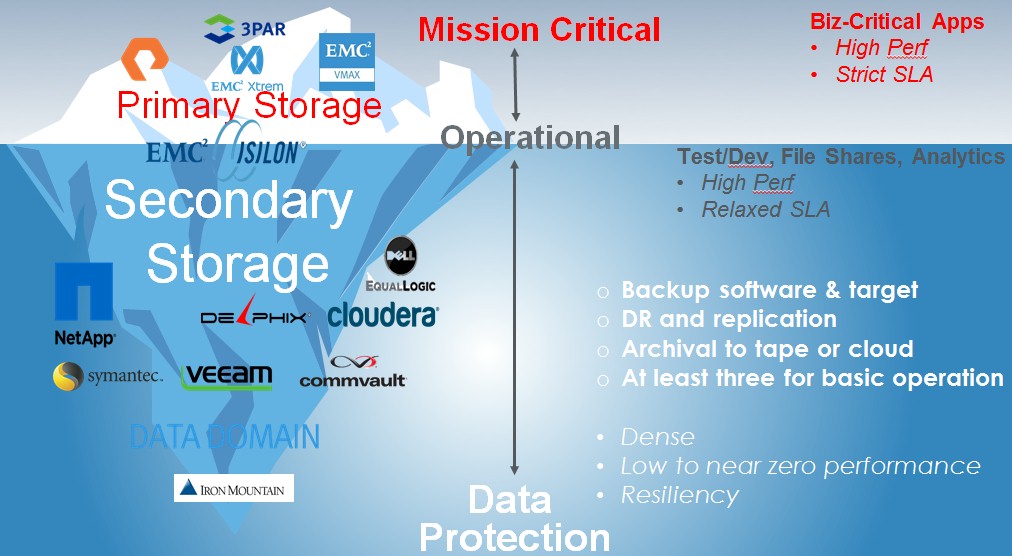
Cohesity wants to bring order to all of this “data chaos,” and in the process, it hopes to take over the role a bunch of pinpoint appliances and software packages that have been running in datacenters for decades. This is a similar play to what Aron and his co-founders did at Nutanix with server-SAN hybrids focused on virtualized server clusters. The workloads that the Cohesity storage platform is aimed at taking over are test and development, archiving, and backup, which makes intuitive sense, but Aron also thinks that the architecture of the storage cluster makes it ideal for running modern distributed analytics workloads based on Hadoop or NoSQL datastores, too. Cohesity will plug into Google Nearline Storage and Amazon Web Services Glacier archival services, and Aron concedes that while these are not as expensive as generic block or object storage on the cloud, Nearline Storage and Glacier are more expensive for large datasets and that Cohesity will probably have to plug into local tape arrays at some point.
It is hard to get a precise feel for how big secondary storage is in the datacenters of the world. It depends on data retention policies and how difficult or easy it is to make snapshots on the existing storage systems. But Aron says that the ratio of tier two to tier one storage is typically in the realm of 3 to 1 in enterprises – and this is after de-duplication and compression is taken into account. Some companies having a very high ratio on the order of 50 to 1 or even 100 to 1 between their primary and secondary storage. So in one sense, it is ridiculous to be talking about how expensive all-flash primary storage is when some of the big money is being spent underneath that production waterline. One early customer of the Cohesity platform is, in fact, moving to all-flash arrays for primary storage, and has been spending 5X to 6X more on secondary storage. The way Aron has done the math, the opportunity is about $60 billion, and that is after removing some overlap in the $45 billion in sales for copy data management productys, $10 billion for purpose-built backup systems, $15 billion for cloud storage, and $20 billion for test and development environments. This is a much bigger target than the $25 billion raw storage array space, obviously, and includes a very large software and support component.
The heart of the Cohesity system is called SnapFS, and it is based on a homegrown distributed object file system that has “infinite scale-out” as Aron put it, global de-duplication, and snapshotting and cloning for data. This snapshotting capability is a key differentiator in that unlike primary storage, SnapFS can take snapshots very frequently.
“The frequency of snapshotting is the key, and the technology that I built in Nutanix cannot even do this,” explains Aron. “No other vendor that I know can do snapshots frequently. In most systems, every time to take a snapshot, you end up forming chains. Every snapshot is a link in the chain. If you take too many shapshots, or take them too frequently, this chain will grow so long that it will hurt your I/O latencies. To keep this from happening, storage vendors have to break these chains, and it is not an easy operation because it involves a lot of copying in the background. If you take snapshots very frequently, you will never be able to catch up. So realistically, you can only take snapshots three or four times a day in most systems. We can take snapshots all day long, every few seconds, and we don’t build chains.”
With the SnapFS file system in the Cohesity platform, the idea of continuous availability is built right in; as new datasets come in or are updated, they are automatically snapshotted. “Gone is the backup window, which exists because of the inability to take frequent snapshots,” claims Aron. SnapFS encrypts all of the data using 256-bit encryption, and the file system also has a mix of SSD flash and disk technology, which is important for the performance of SnapFS. The use of flash in this secondary storage is what enables the high I/O throughput throughput required by test/dev environments, he says. All the different kinds of workloads – test/dev, archive, backup, and analytics – can be run on the system concurrently. At the moment, SnapFS supports NFS access methods and is akin to a distributed implementation of NFS like those used by MapR Technologies and Hedvig, just to name two. But soon Cohesity will support the Hadoop Distributed File System (HDFS) APIs and will be able to speak MapReduce as well. iSCSI block access and SMB/CIFS file access for Windows platforms is on the Cohesity roadmap, too.
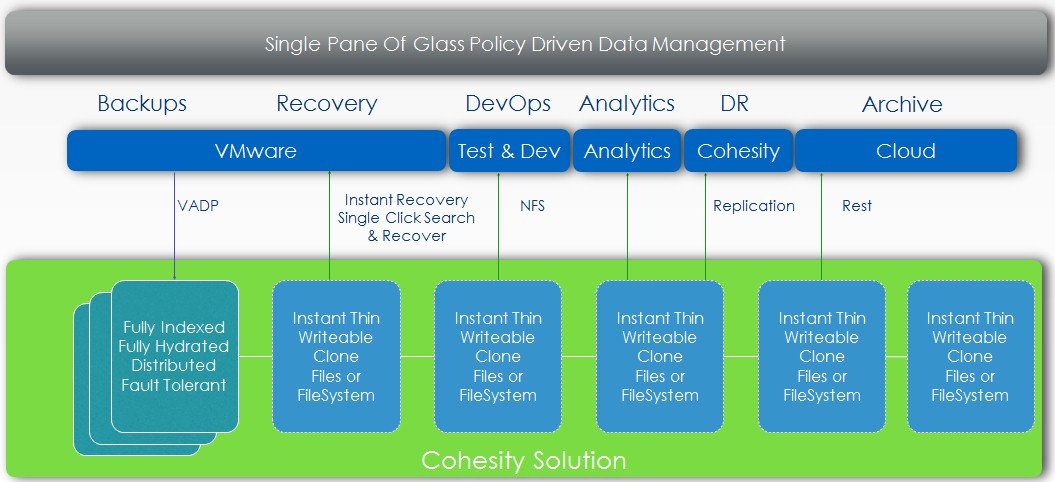
The Cohesity software stack runs on CentOS Linux, which seems to be the preference in that it is compatible with Red Hat Enterprise Linux and free. At the moment, compute and storage are kept separate by Cohesity, with SnapFS only managing the distributed storage, but Aron says the company is looking at adding virtual machines and containers tro its architecture so it can run compute jobs on the storage – much like Nutanix and Hadoop both do. This is one of the benefits of designing a storage system that runs on X86 servers.
Technically speaking, Cohesity SnapFS can run on public clouds and on generic hardware, but the company is starting with an appliance like Nutanix did. “We have a hardware compatibility list of precisely one. But once the HCL grows, we can move to a software-only model,” says Aron. The Cohesity appliance is a standard 2U chassis with four two-socket “Haswell” Xeon E5 nodes, each with six cores. The chassis has 96 TB of disk capacity, 6.2 TB of flash capacity, and eight 10 Gb/sec Ethernet ports. A single Cohesity block with four nodes will cost around $100,000 with all of the software added in, and this is anywhere from a third to a fifth the price of the myriad appliances and storage devices it can replace in the datacenter, according to Aron.
As for scale, Cohesity has only been tested in the lab across sixteen nodes – Aron says that the company has not been rich enough to test across hundreds of nodes – and adds: “We have done this in the past and we are pretty confident that it scales.”
Having deployed GFS and built Nutanix, that is probably not as bold of a claim as it sounds. But pilot customers will be pushing the limits to stress test SnapFS just the same. The SnapFS appliances are in pilot now and are expected to be generally available in late September or early October. After it has been out for a while, support for native Hadoop on the clusters will follow, with support for Cloudera and Hortonworks to start.




Be the first to comment