

The Barcelona Supercomputing Center, which has done a significant amount of research and development on alternative architectures for supercomputers over the years, has just fired up a prototype system based on the kinds of ARM chips that are typically found in smartphones and other client devices. The work to cluster these low-end hybrid CPU-GPU systems is providing the software foundation that could help ARM take on the hegemony of the X86 architecture in HPC and even possibly put hybrid ARM-GPU systems in contention with X86-GPU systems with much more oomph per chip.
The thinking is that for certain massively parallel workloads, a set of relatively wimpy CPUs and GPUs can be lashed together to do the work of a smaller number of larger CPUs or CPU-GPU hybrids. This is exactly how CPU clusters displaced vector machines and massively parallel RISC/NUMA machines in the HPC space starting two decades ago, as project lead Filippo Mantovani, likes to point out in his presentations about the Mont-Blanc project being managed by BSC. The shape of the adoption curve – and the speed at which change comes – in the HPC space is more abrupt than your typical enterprise adoption of a new technology:
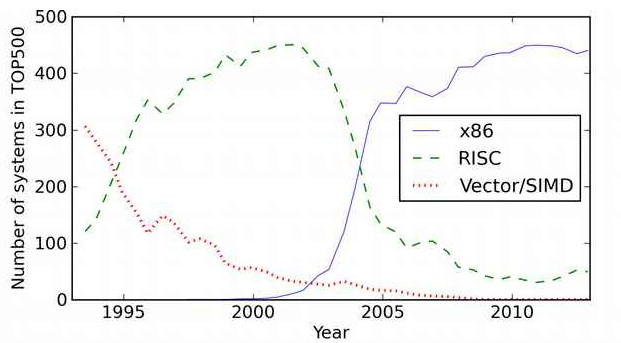
ARM is an indigenous architecture to Europe, so that is one of the reasons why PRACE and the European Commission, which are funding the Mont-Blanc project, like what BSC is doing as it builds its ARM cluster prototypes. But it is more than pride that is at stake here.
BSC, like many other HPC centers around the world and dozens of processor vendors, is trying to figure out how to get to exascale-class systems in a power budget that doesn’t require several nuclear plants to power and cool such a machine. We have hit performance and power walls before in HPC, as Mantovani reminds everyone, and what happened then was the device in a low-end machine was elevated to a server – in this case a PC processor. BSC wants to be ready for ARM in case of an “invasion,” as Mantovani puts it.
This chart is hard to argue with, at least conceptually:
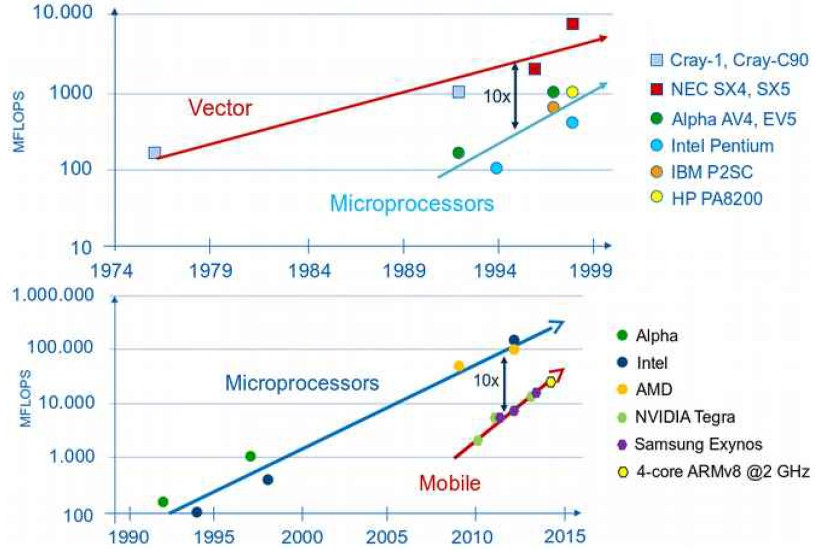
History does not necessarily repeat itself, but it often does, with a twist here and there for good measure. Intel, for instance, is well aware of these charts and has the ability to counter with variants of its Atom and Xeon processors. The impending “Knights Landing” Xeon Phi chip is really a network of stripped down “Silvermont” Atom cores with beefy math units on them, so technically Intel is already reacting in advance of the ARM onslaught, which frankly was supposed to be here a year ago. And if need be, Intel could even go off the board and possibly become an ARM dealer once it finishes its acquisition of Altera, which is an ARM licensee.
This seems unlikely, but so might the idea of peddling field programmable gate array (FPGA) coprocessors to hyperscalers and cloud builders. Intel has shown time and again that it is a chip maker first, and it will shift gears to other compute architectures if need be. That said, Intel will wring every last penny out of its manufacturing prowess and its X86 architecture. This is precisely what any company designing chips for client devices is doing, too. They have to eliminate power and cost much more aggressively than Intel does with servers.
Scaling The Peak
In and of itself, the Mont-Blanc prototype system at BSC does not have a lot of oomph and is not about to unseat any Top500 system. But like the first couple of Beowulf Linux clusters back in the late 1990s, the machines the series of ARM cluster prototypes that BSC has created through the Mont-Blanc project could turn out to be the beginning of a new wave of computing that favors lots of wimpy system nodes over big fat ones. A lot depends on the nature of the parallel applications and how sensitive they are to single-threaded performance on a node, memory bandwidth on a node, and network bandwidth across nodes.
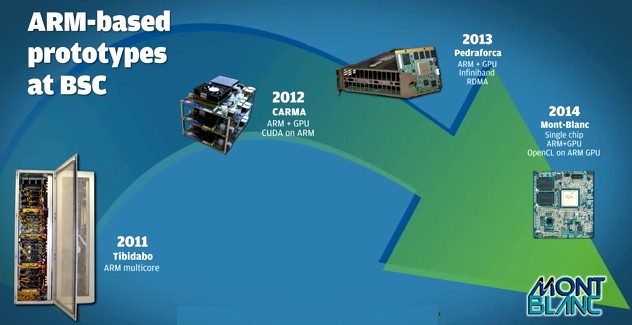
The only way to be sure is to build a system and then put a real HPC stack on it, and this is precisely what the Partnership for Advanced Computing in Europe (PRACE) has been doing since 2011. The Mont-Blanc project was originally given a €14.5 million budget over a three-year term, and it was extended towards the end of that term with an additional €11.3 million to continue the project into 2016. The European Commission has kicked in €16.1 million of the total €25.8 million in funding for the work that has gone into building several of the prototypes.
The first prototype from the Mont-Blanc project came out in November 2011, and was based on Nvidia‘s Fermi GPUs and Tegra3 ARM processors. The final Mont-Blanc prototype, which is the culmination of the first phase of funding, consists of two racks of blade servers that make use of the BullX B505 blade server carrier from French system maker Bull, which is a contributor to the project. For the final prototype, BSC chose the Exynos 5 ARM chip from Samsung, which has two Cortex-A15 cores running at 1.7 GHz. The chip also has a quad-core Mali-T604 GPU, which supports the OpenCL hybrid programming framework that is commonly used on GPUs and increasingly on FPGAs as well. The node has 4 GB of DDR3 memory running at 1.6 GHz welded right onto the system board, and a 1 Gb/sec Ethernet interface that is created from a bridge chip made by ASIX Electronics that converts a USB port into an Ethernet port. Each blade also has a microSD slot of local flash storage that supports up to 64 GB of capacity. All of this fits in a card that measures 8.5 centimeters by 5.6 centimeters.

Each carrier blade in the Mont-Blanc system has fifteen compute nodes, for a total of 30 ARM cores and 15 GPUs per carrier blade. The carrier blade is a cluster in its own right, really, with an embedded Gigabit Ethernet switch, and has two uplinks to hook into top of rack switches that lash the blades in the system together. The complete Mont-Blanc prototype has eight BullX blade enclosures, and sports a total of 72 carrier blades with 1,080 hybrid CPU-GPU cards across two racks. (This is a little bigger than planned.) Add it all up and the system delivers 34.7 teraflops of computing in a 24 kilowatt power draw. That works out to about 1.5 gigaflops per watt, which is a factor of ten better than the original Mont-Blanc prototype that came out in November 2011 and nearly as good as the 2 gigaflops per watt that the most efficient machine on the Green500 supercomputer list could do at the time. As of last fall, the best machine on the Green500 was pushing about 4.4 gigaflops per watt. Hybrid ARM-GPUs are improving fast by these measures, but X86-GPU is not standing still, either, and will continue to improve. The Knights Landing Xeon Phi will no doubt show good numbers here, too.
The Mont-Blanc project has lofty goals, and this includes building a prototype system that will scale up to around 50 petaflops in a 7 megawatt power envelope, making it competitive with the machines on the Green 500 list in 2014. Looking out further, the idea is to design a machine using ARM-GPU compute nodes that can scale to 200 petaflops of raw performance across those two computing elements and do so in a 10 megawatt power envelope and be competitive with the machines that come out on the Top 500 in 2017. That is still only half as energy efficient as the broad exascale goal of putting 1,000 petaflops in a 25 megawatt power budget, but it is a step in the right direction. The advent of 64-bit ARM processors aimed at servers could come into play, if the price/performance and thermals work out. No one has said if PRACE or the European Commission will fund this larger theoretical machine.
In the meantime, the final Mont-Blanc prototype will be used to test the OmpSs hybrid computing environment developed by BSC, which is an offshoot of the OpenMP parallel programming framework and which supports Fortran, C, and C++ code. (It also has hooks into Nvidia’s CUDA parallel programming tools.) Mantovani and the Mont-Blanc partners will be porting a select set of eleven applications to the prototype system, including ones aimed at weather forecasting, electronics structure, particle physics, fusion, protein folding, wave propagation, and combustion.
BSC will also keep an eye on developments in the ARM processor and GPU coprocessor spaces. If something interesting comes along, they will build small development clusters. And based on all that they learn over the next couple of years, the Mont-Blanc team will also provide the initial specs of a future Mont-Blanc architecture that can reach up toward exascale. But again, no one is saying that they will pay for such a system – not just yet, anyway.




Great article — but for me it begs the question of where the much-hyped ARM server parts are, and how are they performing?
With Calxeda dead, Samsung canceling, Broadcom quiet (and perhaps refocusing after acquisition), AMD delaying their custom core by at least a year… and conspicuous silence on general-purpose server performance of the Cavium ThunderX (which as a many core with narrow 2wide in-order cores can be expected to provide poor single thread perf)…
Can we say anything definite on whether ARM is DOA in the datacenter?
It will be interesting to see how these machines perform in HPCG and on the Graph500 as HPL and Top500 become less relevant in the context of useful exascale computing.
Yes, graph500 numbers would be interesting. At least on the A9 parts we tested, they didn’t have enough performance to keep the network busy (that is, keep enough references in flight while exploring the graph).
Seemed better on A15 but still didn’t make sense relative to other architectures.