

There is a disconnect between the database engines that underpin both relational databases and the SQL front ends that have been grafted onto Hadoop analytics tools and the underlying hardware on which these databases run. This is a story we keep hearing again and again at The Next Platform, and Pivotal, which peddles both Greenplum parallel data warehouses and its eponymous Hadoop and HAWQ SQL overlay, is doing something about it.
Specifically, the company, which is a spin-out of storage giant EMC and virtualization juggernaut VMware, has acquired the technology behind a new database engine called Quickstep, which was created at the University of Wisconsin. Jignesh Patel, a professor of computer sciences at the university. Patel and the team that developed Quickstep are joining Pivotal and they will be working to integrate this new database engine into both Greenplum and HAWQ in the coming months.
The development of the Quickstep database engine was funded by the National Science Foundation as well as by search engine giant Google. Patel is a heavy-hitter in the database world. Patel got his masters and PhD at the University of Wisconsin, and his PhD thesis was based on the work he did on the Paradise object relational database management system, which included a geospatial component and was used to analyze satellite imagery. Before the ink was dry on this thesis the work, the intellectual property for Paradise, which was spearheaded by professors David DeWitt and Jeffrey Naughton, was acquired by Teradata (then owned by NCR) for several million dollars. Patel did some research for several years at the University of Michigan and then founded Locomatix in 2008, which specialized in processing geospatial data and social graphs; this company was acquired by Twitter in August 2013 for an undisclosed sum. The financial details of the Quickstep acquisition by Pivotal were similarly not disclosed.
“Quickstep is really about saturating the CPU and keeping it busy all the time,” Gavin Sherry, vice president of engineering for data products at Pivotal, tells The Next Platform. “In order to do this, we will be using the next-generation of hardware instructions inside the CPU, specifically vectorized instructions, and the data will be laid out in memory so that we can really crunch through data at speeds that we have not seen before. And finally, Quickstep is gives HAWQ and the Greenplum database engine a framework to exploit hardware on the horizon or that we haven’t even thought of yet. You can see that GPUs, massive amounts of memory, and other things will fit into our plans.”
DeepIS, which uncloaked its own Deep Engine for MySQL back in April, gets rid of the hard-coded, tree structure at the heart of most database engines and replaces it with an adaptive algorithms that use machine learning techniques as applications are running to optimize reads and writes. It is what amounts to a database kernel and information orchestration system.
Patel says that Quickstep does something similar to optimize its database engine on the fly. “But the second thing we do with Quickstep is to make sure that the raw primitives that you have for crunching through the data are amenable to the hardware as it changes,” he explains. “That’s the part that most people miss. We exploit the fact that at the circuit level in a processor, you have a very high degree of parallelism. So scanning through a piece of data happens very fast because we exploit intracycle parallelism – instead of doing one thing at a time, we do tens of things at a time within a single cycle. It complements and improves upon the dynamic optimization that is already in HAWQ and puts a few more weapons in the arsenal.”
This parallel technique, which is very complex, is called BitWeaving, and you can read an explanation of it here and the full research paper there. The idea is that there is a massive amount of parallelism in modern chips, and as an example, Patel takes the example of adding two 64-bit numbers. Inside the chip, when these numbers are adding, the chip actually has what amounts to 64-way parallelism because it computes on all 64 bits in parallel. Patel and his team created a technique called BitWeaving/V (short for vertical) that allows for parallel operations on bit-level columnar datastores and another called BitWeaving/H that stacks the data up horizontally like a normal database table. With WideTable, Patel and his team have figured out a technique to take a complex set of database tables and flatten their schemas (which describe the shape of the data in tables and their relationships to each other) into one big table, which allows for complex database operations to be performed using simple scans of the data. The kinds of scans that are, as it turns out, massively sped up by the BitWeaving method. (You can read about WideTable here and dig deeper in to the research paper there.)
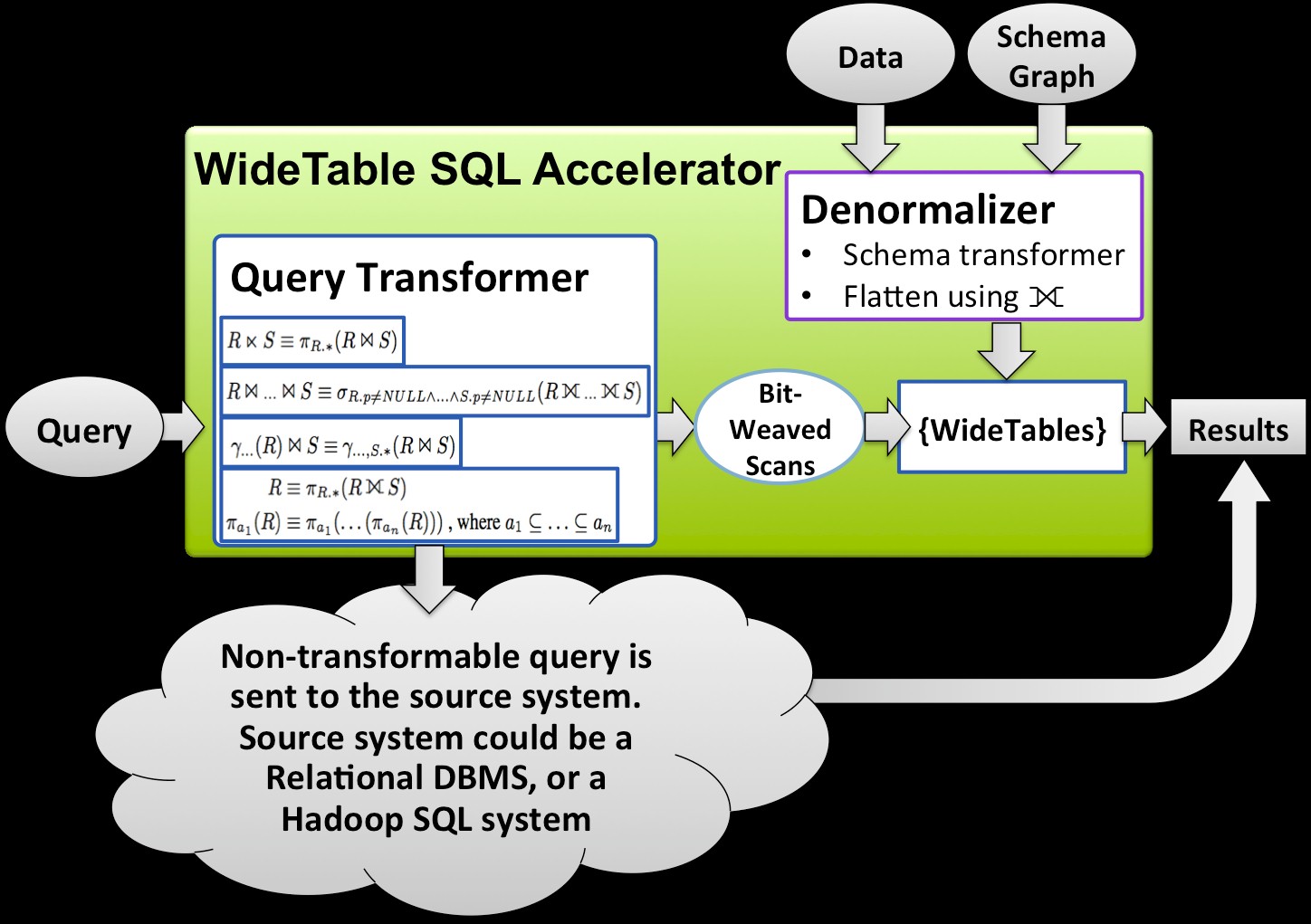
In benchmark tests against the MonetDB columnar database, which dates from the 1990s and is arguably the pioneer in columnar datastores, using the TPC-H data warehousing benchmark, WideTable shows a speedup of anywhere from 2.2X to 154X on a suite of 21 queries. WideTable could not support one of the TPC-H queries and did exactly the same on another. (MonetDB is now owned by IBM after a few years of being owned by SPSS, and it is likely that some of IBM’s DB2 BLU in-memory and columnar add-ons for its flagship DB2 database come from MonetDB.)
The Quickstep project, Patel explains, is specifically targeted areas to improve database performance where researchers have not been focusing in recent years because all of the low-hanging fruit had been plucked, such as doing basic scans, filters, and aggregations. “This is where Quickstep really shines,” Patel says.
The obvious question is why Pivotal, which has so many database and SQL experts, needs Quickstep at all. And Sherry is perfectly blunt about it.
“When I began building the Greenplum database over a decade ago, it was state of the art at the time,” Sherry says. “The hardware model has since evolved and we have been working hard to keep up, but with Quickstep, we are leapfrogging the state of the art by perhaps at least a decade. The framework that the Quickstep team has put together really doesn’t have any precedence in any commercial database and is at the forefront of theoretical understanding and database processing technology. We have advanced query optimization and SQL processing technologies, and we want to complement that with the most advanced approaches to query execution as well.”
Sherry says that Pivotal is starting to integrate the engineers from the Quickstep project with those from the Greenplum and HAWQ teams, and that Pivotal expects to see the first benefits from Quickstep within the next year or so. Sherry can’t be specific about how much Greenplum and HAWQ will improve, but that the expectation is for at least an order of magnitude better performance for both parallel databases and the SQL layer for Hadoop, respectively. In some cases, for certain kinds of applications and queries, throughput or response time could improve by as much as three orders of magnitude.




Be the first to comment