

Enterprises like choices, they abhor vendor lock in, and they like the options that open source gives. But at the same time, too many choices fragments markets and doesn’t allow for the cultivation of larger vendors that can afford to take on the big problems. You need a balance between large enough to scale and so large as to be too overbearing, or sometimes, in the antitrust sense, to be abusive.
With the Hadoop Summit sponsored by Hortonworks going on this week and some tectonic changes in the systems market that have been going on for some months now, we are pondering how this all fits together given the current state of both Hadoop and the systems markets.
While here at The Next Platform we indeed believe that variety makes an ecosystem healthy, we are nonetheless beginning to think that there are too many Hadoop distributions. Three has always been a magic number, as we all know well, which works out to a leader, a challenger, and an upstart in most markets. This triplet helps keep competition intense enough for healthy pricing and yet lets companies make a living and profit enough to plow some dough back into research and development.
We are also starting to think that IBM, which is trying to revitalize and open up its Power chip architecture, might be better served if it would anoint one of the larger Hadoop distros as its preferred stack and to get it all tuned up to run on Power-based servers. Such an approach is probably necessary to take on Intel in the datacenter, which was the really the point of IBM selling off its System x server division to Lenovo Group last fall.
Moreover, given the importance of open source to modern IT applications, it is probably high time that Big Blue open source key components that it sells as adjuncts to its homegrown BigInsights Hadoop distribution, and key among those is The Next Platform Symphony Java messaging platform and the General Parallel File System that is increasingly paired with Hadoop by IBM because of the significant performance advantages it offers.
Those are some pretty big changes, we realize. But the stakes are high, and with Intel being so dominant in systems these days and Cloudera being by far the most heavily funded and largest of the Hadoop distributors – and the one that Intel has an enormous financial stake in – the times call for big moves.
The Big Insight
In the past fifteen years, IBM has certainly leveraged open source to its advantage, but the company is by no means an open source purist. If Big Blue’s Systems Network Architecture was opened up back in the 1970s, we might have had a commercial Internet a lot sooner than we did, and perhaps a better one. But IBM was a company of its time, where software was closed source and proprietary. And for a lot of its key software that it either developed on its own or got through acquisitions, it has kept the source code and the responsibility of further developing that code to itself; it has also largely stuck to a traditional licensing and support model.
Most companies backing an open source project and providing support for it use an open core approach, which means opening up the source code for most of the software and then keeping some enterprise-class add-ons that remain proprietary and that get rolled into an enterprise support contract for the whole stack. The big difference in almost all of these cases is that the cost of the open source tool is significantly less expensive than a proprietary product that it was sort-of replacing.
So, for example, Linux was a fraction of the cost of Unix for roughly equivalent functionality with a lot more portability across server platforms and the benefit of open source. Unix was an open system, meaning there was a modicum of API and command compatibility across different Unix variants, but Linux distros literally run on different architectures and provide the same APIs and commands. The many billions of dollars per year in Unix license and support fees have been utterly wiped from the market and replaced by a much lower Linux revenue stream based on support contracts only – perhaps as much as a 5 to 1 contract comparing today’s Linux with the dot-com bubble when Unix was at its peak. That money that IT shops did not spend on Unix licenses and very expensive (but oh so elegantly designed Unix systems) got poured back into other parts of the datacenter.
We sit now at the beginning of the transformation of the database industry, and while everyone things there is this immense amount of money at stake that will roll from traditional relational databases used in transaction processing systems and from parallel relational databases used in data warehouses, we see another big contraction coming. In time, the Hadoop stack – and we are using this term in the broadest sense, not literally just MapReduce running atop the Hadoop Distributed File System – will absorb all kinds of workloads, and very likely key transaction processing functions, not just analytics. It is just a matter of time and money. This will take time – the rise of Unix took a decade and its fall took as long – and the contraction in the revenue stream is immense. As a gauge, a data warehouse built on parallel relational database costs something on the order of $10,000 per TB, including the hardware, but a Hadoop cluster can bring that down to somewhere between a few $100 per TB to under $1,000 per TB. Depending on the database layers added to Hadoop and the underlying systems. Somewhere between one and two orders of magnitude in savings will shift markets, and as in-memory and SQL processing improve on Hadoop, it will eat more and more workloads.
Don’t get the wrong idea, though. In-memory SQL databases like SAP HANA and MemSQL will find their places and the in-memory variants of Microsoft SQL Server, Oracle’s eponymous database, and IBM DB2 will be around for a long time. We are not silly enough to project that the relational database market will suddenly implode because of the success of Hadoop and its various NoSQL datastore, Spark in-memory processing, and various SQL query overlays. Relational database sales were around $5 billion back in 1995, and doubled by 2005, and are around $26 billion ten years after that and still growing at a 9 percent compound annual growth rate according to the prognosticators at Gartner. We think that Hadoop and its collective of projects takes a big bite out of that RDBMS growth – in fact, they already have – but it is going to take some consolidation among the Hadoop projects and distros before this can happen.
Technically speaking, there is nothing wrong with the BigInsights distribution of Hadoop that IBM has cooked up. IBM invented its own streaming software, called System S and then Streams and now BigInsight Streams, and signed up TD Securities to use it in 2009 running atop a BlueGene parallel supercomputer. IBM is in the process of adding support for Spark in-memory processing to BigInsights, and has taken its own SQL engine and created a Hadoop overlay called BigSQL for executing SQL queries against data stored in Hadoop. (BigSQL is akin to the Impala SQL query engine from Cloudera, HAWQ from Pivotal (which will be employed by Hortonworks), and Drill from MapR Technologies.) IBM has also integrated the R programming language into its stack with BigR, clone of Google’s Bigtable overlay called BigSheets, and has all sorts of machine learning, graph analytics, and sentiment analysis routines in its stack that come out of IBM Research, too. The full Hadoop solution stack from IBM looks something like this:
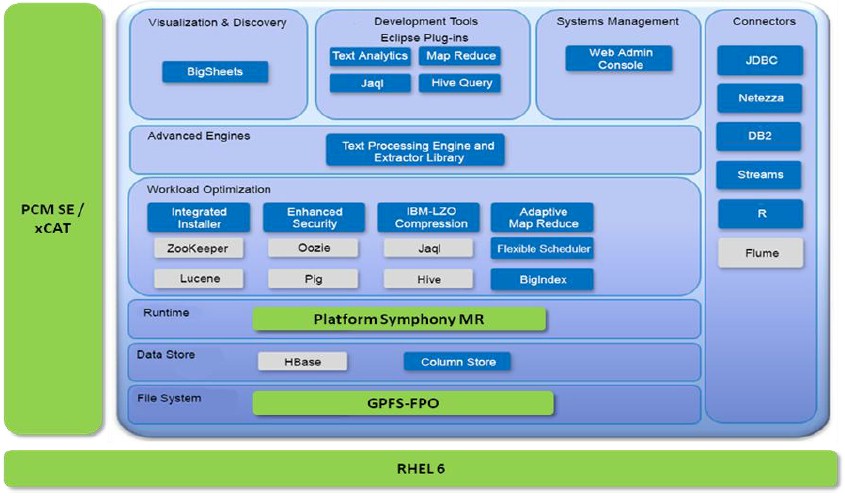
The BigInsights stack has all the elements that a modern analytics workload requires, and then some when you add in Platform Symphony and GPFS, which IBM is rebranding Elastic Storage these days to try to gussie up its HPC image a bit. And IBM has even tuned up its stack to work well on clusters of its Power8 machines. But here’s the problem. Cloudera finished out 2014 with more than $100 million in sales and 525 paying customers. MapR doesn’t give out its revenues, but it says it has more than 500 customers as well. Hortonworks, which is a public company, had $46 million in sales and had 332 customers. We could be generous and call it a cool $250 million in revenues for 2014 and maybe something on the order of $500 million in billings for the whole Hadoop market, and maybe something approaching 2,000 production clusters in the world. This is consistent with what the analysts I spoke to at the end of last year were projecting.
There just isn’t a lot of room for IBM and Pivotal to have their own distros in there. Even if the market keeps doubling for a few years, BigInsights will never be able to catch Cloudera, and IBM very much needs a commercial grade Hadoop stack, including Spark, that is tuned to scream on Power8 and future Power processors. This will not happen with Cloudera, which is very tightly coupled to Intel. The Open Data Platform effort between Pivotal and one of its key investors, GE, along with IBM and Hortonworks is a step in the right direction, but what the industry really needs is a single, third alternative to Cloudera and MapR, which clearly have the lead. And we are beginning to think that what we need is a unified Hortonworks platform that both IBM and Pivotal really get behind, that does further than just ensuring compatibility between IBM, Pivotal, and Hortonworks distros. Pivotal wants to be higher in the stack anyway, and IBM wants to sell systems and services to build clusters and collect support contracts, all of which it can do by opening up and merging all of its technologies with Hortonworks. Or better still, if IBM wants to really become a player, it could acquire Hortonworks and put all of its weight behind a unified BigInsights-Hortonworks distribution. With a $1.15 billion market capitalization, Hortonworks would not come cheap, and IBM would have to pay something of a premium over this amount.
Whether partnering or merging, with this approach, the Hortonworks distribution can be open like IBM is trying to do through the OpenPower Foundation, which is creating an open hardware alternative to X86 systems. And then IBM can peddle a completely open stack.
Time is a-wasting, and it will not be long before the Hadoop stack starts rising up the hockey stick of adoption and, importantly, 64-bit ARM servers come to the datacenter espousing their benefits for running parallel analytics work like the extended Hadoop stack. IBM wants Power to have an advantage for these Hadoop workloads, and it can design accelerators into its processors for these functions – and Intel and Cloudera are no doubt doing right now – as well as in interconnects created by OpenPower partner Mellanox Technologies.
The enterprise datacenter doesn’t need more than three Hadoop distributors, and IBM can’t afford to wait for ARM to become the second most popular server platform for such work a few years hence. If there is going to be a Power resurgence, analytics is going to have to be a big part of that and Big Blue is going to need a bigger base to take share away from Cloudera and MapR.

Intel Pushes Out Hybrid CPU-GPU Compute Beyond 2025
One of the reasons why Intel can even think about entering the GPU compute space is that the IT market, and indeed just about any market we can think of, likes to have at least three competitors. With capital intensive businesses, there is an inevitable consolidation, and sometimes only two …
What Would You Do With A 16.8 Million Core Graph Processing Beast?
If you look back at it now, especially with the advent of massively parallel computing on GPUs, maybe the techies at Tera Computing and then Cray had the right idea with their “ThreadStorm” massively threaded processors and high bandwidth interconnects. Given that many of the neural networks that are created …

Sometimes The Road To Petaflops Is Paved With Gold And Platinum
Supercomputing, with a few exceptions, is a shared resource that is allocated to users in a particular field or geography to run their simulations and models on systems that are much larger than they might otherwise be able to buy on their own. Call it a conservation of core-hour-dollars that …
Be the first to comment