

The build versus buy argument for high performance computing clusters has gathered steam lately, in part because some of the critical missing pieces both performance and software ecosystem-wise are snapping into place.
It has taken a number of years to get to the point where HPC in the cloud is practical—at least for some applications. While the large cloud providers have added hooks for HPC in terms of more powerful networks and processors, and others like Rescale have solved some of the required HPC software puzzles by getting ISVs with HPC code to flex their license models, there is still the tricky problem of deciding what to run in the cloud, what to save for the on-premises HPC cluster, and what might be best served by a bursting models that leverages both simultaneously.
As The Next Platform explored in another recent article, the build, buy, or co-locate decision is difficult outside of HPC. In an effort to get a better sense of how the argument between these is being presented, we were able to procure some numbers from Rescale, which is an HPC cloud provider (as described, particularly in terms of its software hooks for HPC ISVs here).
The numbers below back Rescale’s argument in the cost breakdown for on-site HPC clusters versus renting capacity and licenses, and represent the costs of a typical, middle of the road cluster for high performance computing workloads, without the highest-end processors and without any accelerators. In a follow-up article to explore the costs of HPC clouds, Rescale CEO, Joris Poort explained that this represents a midpoint for end users—some want ultra high performance, others are cost-conscious, hence the choice for this as the baseline. Naturally, once the newest Haswell processors or Infiniband or other bells and whistles are added the base costs go up, especially for the first year of the cluster.
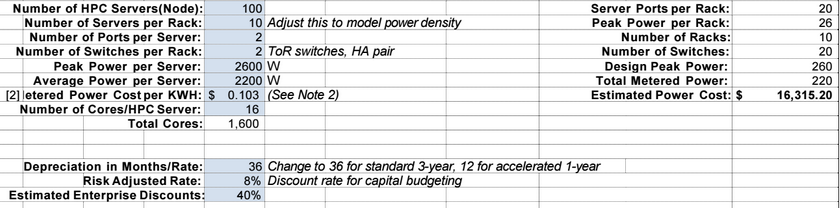
With the above configuration, users are looking at close to $70,000 per month just to operate a typical 100 node cluster in a physical datacenter, with around $16,000 of that cost going toward power and cooling. The figures Poort provides also include one full time engineer to manage the cluster, which he says is often not a position that disappears since most of their users, and those who have made a cloud transition, are still running many workloads in house in addition.
Here is the breakdown Poort provides of typical cluster costs:
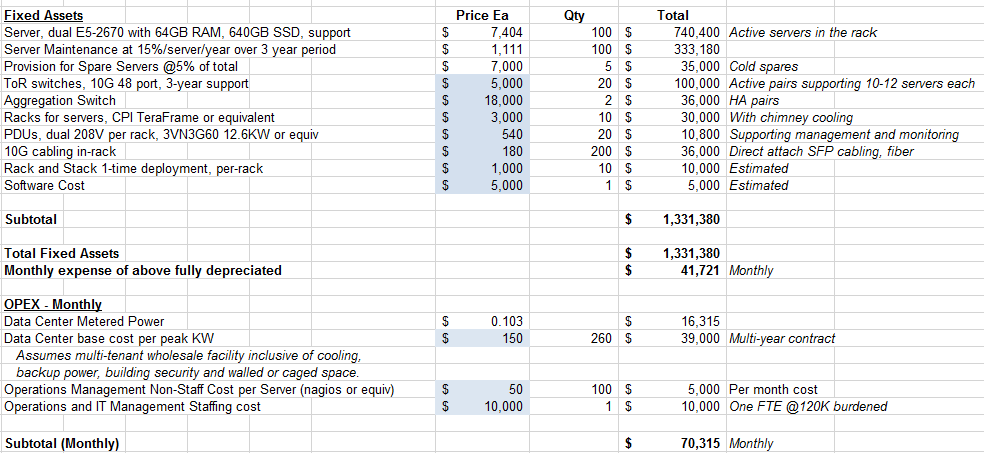
That is just the cluster operation, but Poort says the cost total for owning the cluster, including the support staff and other services as broken down in the charts provided, is more like $110,000 per month. The interesting part about that is that approximately $40,000 are hardware related costs, but the other almost $70,000 is operational (power, people, and related costs).
This might sound high, especially for companies where the budgets for HPC resources are broken down across divisions. For example, in some organizations, the cost for things like bandwidth are billed as part of a larger bandwidth usage monitoring mechanism. The same is true with electricity use, which is oftentimes not part of the total for an HPC cluster since the datacenter consumption is rolled in with other electricity usage. All of these funds do come from somewhere, but Poort says he realizes its easy to take issue with how large these figures are—they are simply rolling together all possible costs, even in some HPC shops pass certain large bills for their facilities to other departments.
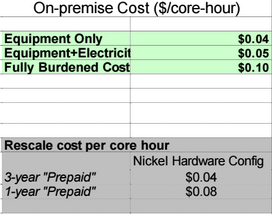 On that note, breaking down core hour costs is a little tricky, especially since oftentimes this is calculated based on hardware costs alone. The part that is often missing from these calculations are the many other costs that are factored into the overall operational and datacenter costs as listed above. The fully burdened core hour costs at 10 cents per core hour does factor all of this in, but it’s a matter of how shops calculate these things. “If you’re adding just electricity and not all the datacenter costs, then you’re at 5 cents per core hour, which might not sound like much a difference, but it’s 25% more—then you add in those facility costs and other elements and it’s quite a big deal,” explains Poort. These are not savings that would be immediately realized, either, which is an important distinction, but over time, the difference could be quite significant.
On that note, breaking down core hour costs is a little tricky, especially since oftentimes this is calculated based on hardware costs alone. The part that is often missing from these calculations are the many other costs that are factored into the overall operational and datacenter costs as listed above. The fully burdened core hour costs at 10 cents per core hour does factor all of this in, but it’s a matter of how shops calculate these things. “If you’re adding just electricity and not all the datacenter costs, then you’re at 5 cents per core hour, which might not sound like much a difference, but it’s 25% more—then you add in those facility costs and other elements and it’s quite a big deal,” explains Poort. These are not savings that would be immediately realized, either, which is an important distinction, but over time, the difference could be quite significant.
The catch is, that 10 cents per core hour is assuming 100% utilization, as you can see in the chart below. “Another big misunderstanding when it comes to evaluating these costs is when one just looks at the surface at how much they are paying for a server in the cloud. The cost seems high relatively to just buying a server and plugging it in yourself, but the reality goes back to utilization—you can spin these machines up and down, you’re not paying for them when you’re not using them,” Poort says.

In other words, with a typical on-premises system, this is not the case and for many HPC engineering groups, the tendency is to plan for peak capacity since having the full resource push for product development is oftentimes more important than worrying about having 100% percent utilization. “A lot of companies understand that they are getting maybe 60-70% utilization, but that’s a smart decision on their part because they need that peak capacity—their engineers cannot wait for simulations to run.”
This goes back to Poort’s argument that the ideal use case for HPC customers is to have some combination of on-premises and cloud-based resources to manage the need for peak capacity, but also to balance the costs based on existing hardware investments. He does not expect companies to go full-bore into the cloud for all of their critical HPC workloads, but does see an opportunity to expand access to both the needed diverse hardware and software tools to expand a company’s existing capabilities.
As a final note, part of what we described in a previous article about Rescale was not so much about the hardware available from its collection of resources around the world (1400 petaflops of potential peak), it was more related to the software license agreements they have managed to arrange with ISVs offering expensive, complex HPC engineering software. For a user to buy these licenses by the hour is an important (and unique) capability, which adds (rather significantly in some cases) to the prices shown above. Still, to see the hardware costs broken down from cloud vendors–and how they approach potential users is valuable insight, although the variability of HPC systems and workloads makes it difficult to set a baseline that is applicable to all.



Be the first to comment