
After several years of development, the Google-inspired Apache Drill tool for doing complex, ad hoc queries against various levels of structured data, is ready to move from project to production. So says MapR Technologies, the commercial Hadoop distributor that has been spearheading the development of Drill, which is the company’s effort to supply an SQL query method that will span everything from document data stores to relational databases.
The Drill tool also does something that HBase can’t always do when it is running a query against a very large dataset: Finish the job at all. Given this, it is possible that Drill could see broader appeal – and maybe even commercial support – outside of MapR’s own Hadoop stack. This, among other reasons, is why Pivotal is working to open source its own SQL layer.
Every Hadoop distribution has its own variant on the SQL theme: Pivotal and now HortonWorks have HAWQ, which is derived from the SQL query engine inside the Greenplum parallel relational database used for data warehousing. Cloudera has Impala, which is a distributed query engine written to run atop of the Hadoop Distributed File System or its HBase tabular overlay for data warehousing and the Hive query tool. Impala was inspired by the F1 fault tolerant distributed relational database management system that underpins Google’s AdWords ad serving systems, and the Impala project was run by Marcel Kornacker, who was one of the architects of the query engine inside of the F1 database. The Apache Drill project being championed by MapR gets its inspiration from Google’s Dremel tool, which is yet another means of providing ad hoc querying capability for a columnar data store called Bigtable. The Bigtable database layer has been in use as the backend for many of Google’s search engine and advertising applications for more than a decade and this month was exposed as a service on its Cloud Platform public cloud. Bigtable was the inspiration behind the DynamoDB NoSQL database that Amazon created as the back-end for its online retailing operations several years later and also for the Cassandra NoSQL data store created by Facebook a bit later than that.
The point of all of these tools is that companies want to be able to query their unstructured, semi-structured, and structured data using something as close as possible to the SQL query language that has dominated the data processing industry since relational databases came on the scene in the late 1970s, grew in popularity in the 1980s, and became standard in the 1990s for transaction processing and analytics.
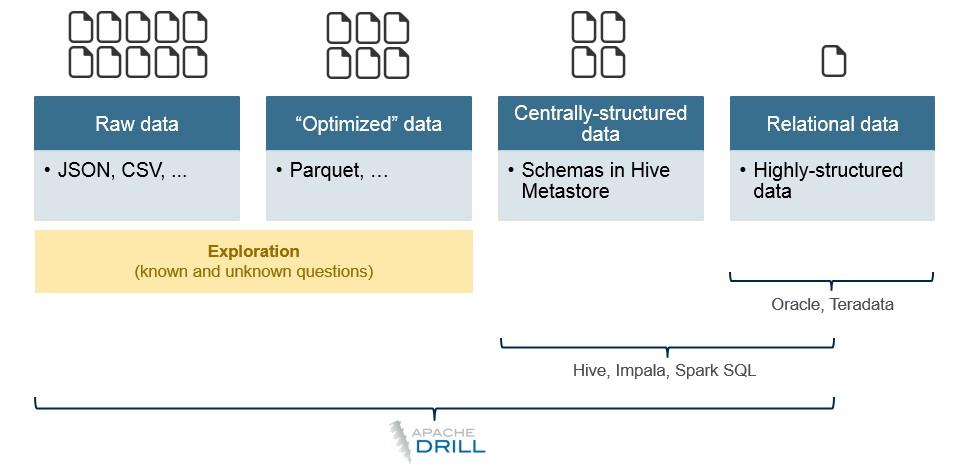
The problem is, all of this machine-generated data has to be massaged and organized with schemas and indexes as it is pulled into relational databases (whether these databases run on a big NUMA box or in parallel on a database designed to scale out across multiple nodes). In fact, Yahoo created Hadoop in the first place because, like Google, it did not want to do the extract-transform-load (ETL) process that slows down doing the analytics on advertising and clickstream data, but do the queries on the raw data as it was coming in.
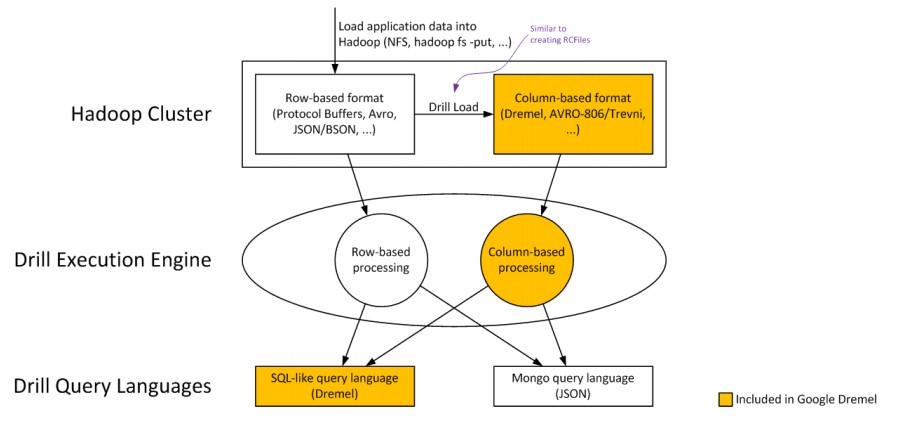
Drill initially stored data in Avro, JSON, BSON (the format for the MongoDB document-based NoSQL database), and protocol buffer formats and was created to be able to query anywhere from gigabytes to petabytes of such data in anywhere from milliseconds to minutes – useful for situations, like real-time dashboards or event-driven applications where low latency is important and so is a breadth of data. And with most organizations storing machine-generated data in a JSON or some variant of that document format, it is obviously very important to create a query method that can chew on JSON documents as well as on other formats while at the same time also have JDBC and ODBC drivers that allow it to simultaneously tap into and query information stored in relational databases.
Drill has been in development for a number of years, and was incubated as an Apache project back in September 2012. Its data formats have expanded over time as it has headed towards commercial release, and Jack Norris, chief marketing officer at MapR, quips to The Next Platform you can download Drill and run queries against all of the data stored on your laptop if you want to.
But this is not the design point of the Drill tool. Rather, it was designed to run queries across thousands of nodes in a cluster with petabytes of data with thousands of end users banging away queries on that data. This is, roughly speaking, the same scale that Google says it has for the Dremel tool, which is used on its internal and now external BigQuery service.
Drill is also unique, says Norris, in that it was designed to scale across more data types than other ad hoc query methods for data in various stages of structure. Drill supports ANSI SQL standards, so users familiar with relational databases or the many tools that hook into them can ride atop Drill. One of the key differentiators with Drill is that it can discover the schemas that describe the tables, indexes, and other features of a dataset. Drill initially was going to support the DrQL query language, a special variant of SQL that aims to be compatible with the language Google created for the BigQuery service, and it has a plug-in architecture so other query languages can snap in, such as Mongo Query Language. As it comes to market, Drill supports ANSI SQL operations but it is not clear at press time how much of the entire set of ANSI SQL statement is supported. (The distinction is important.)
Drill can query data stores that have schemas (protocol buffers, Avro, CSV) and those that don’t (such as JSON and BSON), and can extract data from row-based data stores (Avro and RCFile) and columnar data stores (protocol buffers, Avro, JSON, BSON, CSV, and Parquet). The tool has hooks for relational databases as mentioned above, and can reach into the Hive and HBase layers of Hadoop as well as handling MapR-DB formats. (MapR has created its own NoSQL data store that is compatible with HBase, which is called MapR-DB.)
The source code for Drill is open source, so anyone can in theory integrate it with a Hadoop stack, but at the moment, for obvious reasons, Cloudera, HortonWorks, and Pivotal are not supporting Drill with their distributions. Drill will work with MapR’s freebie M3 community edition of Hadoop as well as with its Enterprise Edition, which includes extra goodies like MapR FS, the company’s HDFS-compatible file system that runs anywhere from 3X to 5X faster than HDFS, plus commercial grade support for around $4,000 per server node per year. The Enterprise Database Edition adds in the company’s HBase-compatible database layer, which is faster than HBase and adds a bit to the license and support price. Drill is an add-on for all three editions, and commercial support costs $1,750 per node per year. A MapR Hadoop and Drill query stack is still a lot less expensive than a parallel data warehouse software running on similar iron would be. Like an order of magnitude cheaper. One unnamed financial services giant that MapR is working with is planning to replace its data warehouse for credit card fraud detection with a Hadoop/Drill cluster that will get the cost of storage down to $1,000 per TB, according to Norris.
The question is, can Drill provide similar performance to other SQL layers running atop Hadoop, and how does it stack up to other methods of extracting information from relational databases and other NoSQL data stores? Norris says that now that Drill is available in a 1.0 release that is ready for production use (that’s about a year and a half later than planned, but this is complicated software being developed by an open source community that is less worried about an upgrade cycle and more worried about getting something right), it is working on some TPC query benchmarks right now to see how Drill stacks up to other query tool and database/data store combinations.
“Some of them are a lot faster, and some of them are a little slower,” says Norris. “It depends on how narrow the workload is. If you highly structure the relational data and set up the right star schema and process that with Teradata, you will get some blazing speed that is faster than what you would get with Drill on the far right of that chart above. But that is a little bit apples and oranges in terms of measuring speed. Are you only measuring when the query action is happening? You have to move data into the data warehouse. You might want to query it when the data is created. If that is the case, you are on the far left side of the chart above, and we kill them in terms of performance because you don’t have to do ETL.”
Where this all gets interesting is when companies want to combine their transaction data from relational databases with social media or other kinds of unstructured data and do queries. And companies want to have applications that can mash up all of this data to start anticipating changing business conditions, not just reacting to it.
“If there is a theme here, it is about helping companies impact business as it is happening, not having a more sophisticated reporting function,” says Norris. “It is not just about providing insight to an analyst, but driving this whole process where companies become more data driven and more agile. Drill is often a piece of that. There is a lot of stuff going on.”
Drill is often being used to understand data that is coming in before it is added to operational applications, and in other cases, some companies are thinking about using Drill as the main tool for doing queries across their various data stores and databases. The other thing to consider is that certain kinds of queries simply will never complete on datasets pumped into relational databases or Hive on top of Hadoop on the right of that chart. In a sense, completing the job at all is infinitely faster than never completing it.
MapR will be providing some benchmarks as soon as they are finished, and Norris hints that for future releases of Drill MapR and the open source community contributing to the project will be doing more work to boost the performance of Drill when it is working with relational data and eating more complex SQL queries.
The thing to remember is that Drill is not intended to be a business intelligence tool in its own right, but to interface with tools from Qlik, Tableau, MicroStrategy, and others; it does have a feature called Drill Explorer that is used by data scientists to surf through a dataset to get a handle on what is in it, but this is in no way a query tool suitable for doing queries. The other important thing to remember is that Drill is absolutely not dependent on Hadoop, even though it meshes well with it.

Be the first to comment