

The name of the game among the hyperscalers is to use their hardware and software engineering to get their infrastructure compute and storage costs coming down faster than the rate of Moore’s Law improvements for the components that make up their systems. Some of that motivation to outpace Moore’s Law comes from the fact that IT is the main cost at these companies and that any improvements drop to the bottom line. But for companies like Google and Microsoft, who are competing against public cloud juggernaut Amazon Web Services, the reductions in the cost of computing and storage capacity mean that they can chop prices and try to undercut AWS and steal some market share.
Is such aggressive and sustained price reductions for virtualized infrastructure sustainable over the long run for any of the cloud providers? Or is this a strategy that cannot apply to those cloud providers that operate at a smaller scale than AWS, Microsoft Azure, and Google Cloud Platform?
Passing through some of the savings as Google gets less costly compute and storage is precisely what the company committed to doing last year, and it is keeping good on that promise with price reductions on its public cloud. The search engine giant, which wants a much bigger piece of the cloud computing pie than it currently has, is also introducing its own variant of Amazon’s spot pricing for compute instances – called Preemptible VMs – that will help lower costs further than the other aspects of its pricing, such as per-minute billing and automatic discounts for sustained usage of on-demand instances. (Google does not yet offer reserved instances, and Microsoft doesn’t offer reserved instances per se, but does have enterprise license agreements for large customers who buy Azure cloud capacity in bulk.)
The advent of preemptive VM pricing on Google’s Compute Engine infrastructure cloud suggests a few things. First, that Google has enough spare capacity in its datacenters when it is not loading up its own workloads on its systems that it can take on occasional work that might otherwise leave capacity just spinning in place and creating heat. (As James Hamilton, who runs the infrastructure at AWS and who used to do so at Microsoft, has pointed out in the past, the stupidest thing you can ever do is turn a server off. You find work for it to do because it is a sunk capital cost that you have to recoup.)
Moreover, the spot instances on Compute Engine also suggest that Google has a large enough and diverse enough customer base with varying compute needs and ever-present budgetary constraints to eat up that excess capacity in an orderly fashion when spread over that customer base. No cloud provider can add spot pricing to cloudy infrastructure unless and until it has a fairly good idea of how much capacity customers might need, particularly for parallel workloads that will speed up completion time on work instead of adding new workloads to the system, and do so for a lower overall cost of compute. But you can immediately see why spot pricing is appealing, because it allows for customers to eat up spare capacity that might not be making any money for the cloud at all while at the same time shaving a bit off the capacity expansion needs at the cloud providers. As customers learn to juggle on-demand, reserved, and spot instances for their workloads, they help drive up utilization on server and storage clusters.
It is a win-win-win for everyone involved.
As Google explained when it took the cloud price war to a new level last March, chopping its Compute Engine instance prices across the board by 32 percent, cloud pricing is not keeping pace with Moore’s Law. And Google thinks that it should, and customers would not argue.
By his math, Urs Hölzle, senior vice president of the Technical Infrastructure team at the search engine giant and one of the top four public cloud providers, said that cloud infrastructure prices were coming down by maybe 6 percent to 8 percent per year while the costs of systems was improving on the order of 20 percent to 30 percent. There has to be something of a gap in there to cover the manufacturing and maintenance of systems because people get more expensive over time, not less so, but even still, Google wants to compete by getting cloud pricing closer to a Moore’s Law curve. The price reductions were part of that, and so were automatic discounts for customers who had sustained use on the capacity they buy on Cloud Platform. So was per-minute rather than per-hour billing, which Google introduced first, and the price reductions announced this week by Google along with spot pricing push the Google prices down even further. (You will note that Google did not offer spot prices on Compute Engine last March, when it first started talking about getting cloud pricing on the Moore’s Law curve. No doubt the company could have, but perhaps it wanted to keep this maneuver in reserve for 2015, when its customer base was a bit larger.)
Things are different at hyperscale than they are within the typical enterprise datacenter. Capacity planning is not a precise science for individual companies, but for Google’s own work (lots of applications running on thousands of nodes each, adding up to more than 1 million nodes in the aggregate) and for the tens of thousands to hundreds of thousands of customers it must now have on Cloud Platform, it is much easier for Google to do capacity planning. Microsoft and Amazon both have indicated in past conversations with The Next Platform that capacity planning is not much of an issue with them, as hard as that might be to believe. The spikes and valleys even out over large numbers of users and across time zones, and the customer base is growing predictably, too. Ponying up the capital to buy the capacity is a big deal, and so is getting a supply chain set up with multiple sources of customized gear to meet those capacity demands.
The hyperscale public cloud operators buy systems by the truckloads – quite literally – and their cost of capacity is coming down every year thanks to precisely customized systems and the extreme volume pricing that they can command for individual components direct from their suppliers and for system manufacturing. The Open Compute Project started by Facebook seeks to bring the advantages of hyperscale to other enterprises, but thus far the grief of changing system vendors has been too high compared to the benefits because most enterprises buy systems in the dozens or possibly the hundreds, not in the thousands or tens of thousands. Companies can and do get some advantages by going with semi-custom machinery from Dell, Hewlett-Packard, Supermicro, or Quanta.
How Low Can You Go?
There are many analogs in the IT sector for the price war that is going on between the top three public cloud providers and that, because of their lack of similar scale, the remaining dozens of cloud capacity suppliers cannot make. Google, Microsoft, and AWS all have well north of 1 million machines in their fleets. Based on some information that AWS has given about its datacenters, the number of machines in its fleet could be anywhere from 1.4 million to 5.6 million, and we think it is north of 3 million; Gartner estimated it at around 2.4 million last year. Gartner also said that AWS had five times as many servers as the next fourteen cloud providers added up. Rackspace Hosting and IBM SoftLayer are operating considerably smaller fleets. Rackspace had 114,105 machines as of the end of March, according to its financial reports, and SoftLayer had over 100,000 machines in its fleet as of January 2014 and was adding around 20,000 machines per year in the wake of the IBM acquisition, so it should be at around 125,000 servers by now. The server counts tail off very fast once you get outside of AWS, Google, and Microsoft.
This does matter, at least for now as most clouds are based on either bare metal machines that are essentially hosting either single apps or nodes of clustered applications or virtual machine hypervisors that are, at least compared to software containers, have very high overhead. All of that bare metal iron can be shared across time, but not within a span of time. So there are limits to driving up utilization, and that means it is hard to amortize the cost of this bare metal across various workloads and customers.
This is why bare metal provisioning of server nodes like that which is now available inside of OpenStack through its Ironic feature is a key development. Anything that speeds up the deployment of apps on bare metal will drive up utilization. And if containers can pack more jobs onto a machine, even if they were not intended to be a replacement for server virtualization, in some cases, to push up utilization, the combination of bare metal provisioning and software containers could supplant hypervisors and virtual machines out there on a portion of the cloud, if for no other reason than to drive that Moore’s Law curve for the cloud providers. In many cases, containers will run atop virtual machines, of course, which provides heightened security and workload management but also eats up some of the capacity of the iron and hence chews into the Moore’s Law gains.
As far as customers are concerned, Google’s commitment to bring the pricing down on its Cloud Platform is wonderful, and presumably it means it will be fairly predictable, too. And here is how the company says it is tracking since its Compute Engine infrastructure cloud was launched in November 2013:
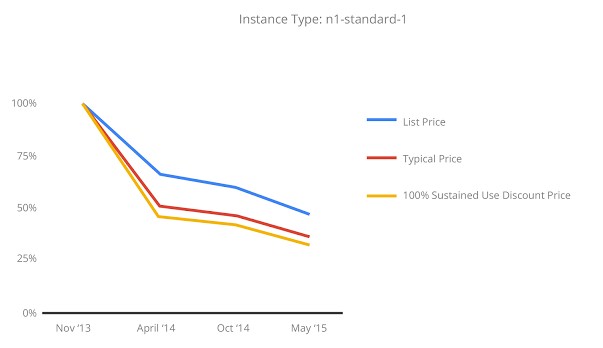
No cloud provider wants to charge one penny less for capacity than it has to, and the fact that Google has reduced prices by 50 percent on Compute Engine capacity in the past eighteen months is not necessarily an indicator that it can do that every eighteen months, and it certainly does not mean that prices will come down uniformly across all compute and storage capacities. In fact, Compute Engine pricing was cut uniformly a year ago, but different instance types got chopped by different amounts. The micro instances saw a 30 percent cut, while standard instances had a 20 percent reduction, small and high-memory instances saw a 15 percent reduction, and high CPU instances only got a 5 percent cut.
The typical price shown in the chart above is literally the price all customers using Compute Engine paid for that particular instance type, averaged out, and it seems to imply that a large percentage of Google’s customers are getting the benefits of its sustained use discounts, which automagically apply to on-demand instances on Compute Engine. As the usage of an on-demand instance rises over the course of a month, the discount on the instance rises. If you use an instance for 25 percent of the month or less, you pay the full base rate, and this scales up to a 10 percent discount if use it for two weeks of the month, 20 percent for three weeks of the month, and 30 percent for the whole month. (The pricing is not done on a weekly basis, but hourly, but we gave the example that way to simplify it.)
Google’s desire, of course, is to be able to schedule as much of its demand as possible as early as possible and for as long as possible on Cloud Platform. And the preemptible VM instances are another tool to do just that. In this case, the demand may not be as predictable as the supply, or both might be relatively chaotic. (Only the cloud suppliers know this, and even they would probably warn, like Wall Street, that past performance does not guarantee future performance.) With the preemptive VMs, which are available in all Cloud Platform regions in beta form, Google is chopping the price by 70 percent for all instance types; the caveats for these new instance types are that Google can shut them down at any time, the maximum runtime for work running on them is 24 hours, and you cannot live migrate running VMs to on-demand instances. The obvious use case is for applications that process work in a distributed fashion and can take a loss of nodes at any time and still keep working. Think of the triplicate data storage that is common with Hadoop and MapReduce, for instance. You could park some of the application on instances with on demand pricing and some on those with preemptive pricing. Think of it as a way to turbocharge an existing set of on demand instances, not as a way to get capacity on the cheap.
The Moore’s Law Flaw
It is important to note that Google said last year that its pricing would track Moore’s Law, presumably not the improvements in capacity but the resulting improvement in cost per capacity. What this almost certainly means is that Google will never put its pricing on a more aggressive curve than that unless it needs to as a means of getting under the prices that AWS or Azure charge. This also means that as the Moore’s Law curve flattens for compute and memory and other storage, so necessarily will Google’s price decreases.
Here’s the rub. As the cost of capacity comes down and the prices follow suit, the operating margins do, too. And thus the cloud providers will have to make it up in volume just to keep their revenues and profits where they are. To actually increase profits year on year, they will have to grow their businesses even faster than that.
So the real question becomes: Can the public cloud sustain revenue growth of, say, more than 40 percent per year over the long haul and still provide increasing profits that investors in Google, Microsoft, and Amazon expect? Over the short haul – such as the past nine years as AWS was ramping and over the next, say, five or six years until the actual Moore’s Law starts hitting some physical limits in compute – this seems reasonable.
But at a certain point, the Moore’s Law improvements will slow until the cost of compute, storage, and networking capacity starts coming down again owing to some new technical advance. The cloud providers will be hard pressed to drop their prices and eat into their profits until that new technology comes along, but competitive pressures could continue the price war, where they have to not only cut into the fat, but into the flesh and hit the bone to maintain top-line growth. It has happened before, with PCs and servers, and there is no reason why it won’t happen with cloud capacity when the big want to get even bigger.

Cerebras Smashes AI Wide Open, Countering Hypocrites
We could have a long, thoughtful, and important conversation about the way AI is transforming the world. But that is not what this story is about. What it is about is how very few companies have access to the raw AI models that are transforming the world, the curated datasets …

How AWS Can Undercut Nvidia With Homegrown AI Compute Engines
Amazon Web Services may not be the first of the hyperscalers and cloud builders to create its own custom compute engines, but it has been hot on the heels of Google, which started using its homegrown TPU accelerators for AI workloads in 2015. AWS started with “Nitro” DPUs in 2017 …

Hyperscalers Set The Pace For 800G Ethernet
The hyperscalers and the largest public clouds have been on the front end of each successive network bandwidth wave for more than a decade, and it only stands to reason that they, rather than the IEEE, would want to drive the standards for faster Ethernet networks. That is why the …
Be the first to comment