

It is safe to say that there have never been more ways to store massive amounts of data of varying degrees of structure and to dice, slice, and correlate that data to gain some insight from it. But most analytic tools require specialized knowledge, and even familiar SQL overlays for tools like Hadoop are often a bit clunky and unfamiliar to those who cut their teeth on relational databases. Analytics is still hard, and there is no easy way to collaborate across end users with differing levels of expertise in chewing on large datasets.
Adatao, a startup founded by a former engineering director in charge of the Google Apps stack that has bet heavily on the Spark in-memory add-on for Hadoop, wants to change all of that. And it wants to help enterprises get hyperscale-style analytical tools that move from simple historical analytics to prescriptive analytics driven by deep learning.
The company has uncloaked from stealth with a more natural interface for querying data, which The Next Platform has seen in action. Equally importantly, Adatao has also come up with an abstraction layer that sits between common programming tools and many different kinds of data sources, masking them from users but also allowing for sophisticated applications using predictive analytics and machine learning to be created using R, Python, Scala, Java, SQL, or other programming languages.
Christopher Nguyen has a long history in the IT sector, and whole he was getting his compsci degree at the University of California at Berkeley back in the 1980s he wrote some of the original TCP/IP stack for BSD Unix. Nguyen got his masters and PhD in electrical engineering from Stanford University, and was a professor at the Hong Kong University of Science and Technology for a few years before working at a number of startups, and then he joined Google as engineering director for Google Apps, the suite of office automation and collaboration tools that is anchored by Gmail, which has north of 500 million users worldwide.
“Big data is enough data for machine learning. We are at the threshold of a new age in machine intelligence, and a lot of exciting things are happening at Google, Baidu, and Facebook. We are all about tracking this curve.”
Adatao is trying to position itself between the confluence of ever-cheaper compute and memory in clusters and the rise of deep learning applications, which teach themselves correlations between datasets, that augment traditional data warehouses and dashboard analytics tools used by enterprises the world over. As Google has proved, more data trumps a better algorithm every time, and with deep learning, you let the computers chew through the data and automatically make the correlations that people might never be able to see no matter how much time they had.
Nguyen does not like the classical definition of big data any more than we at The Next Platform does, and says that the velocity, variety, and volume statistics miss the point of what is actually going on. We suggested that there has always been more data than companies could process, and that the only thing that is new is that storage costs have come down enough that more of it can be stored and main memory costs and compute have come down enough that more of it can be chewed on and correlated. In this respect, it is more saved and used data than big data. Nguyen says this is precisely right and then added this qualifier.

“Big data is enough data for machine learning,” Nguyen explains as he walks through the curve shown in the graphic above. “We are at the threshold of a new age in machine intelligence, and a lot of exciting things are happening at Google, Baidu, and Facebook. We are all about tracking this curve. In the past, with business intelligence it was about how much money a company got from selling a widget; it was all about slicing and dicing historical data. We graduated from the descriptive phase to inferential, where we tried to figure out if a 1 percent change in marketing would lead to a 5 percent change in revenue, for instance. Today we are sitting at the predictive phase, where we can grow data with the hardware and have our algorithms learn patterns and deduce things that the human brain alone cannot. Adatao users can ask a simple question, such as what will the next 30 days of sales look like, and we can project that. Within the next five years, we will be in the prescriptive phase, where we can tell business users what actions they should take. Adatao is all about tracking this curve all the way to machine-augmented human intelligence, and the curve is inevitable because hardware and software architecture are both tracking this curve, so big data is, in many ways, not a coincidence.”
Adatao is not creating a new machine learning stack, but rather a framework for snapping various disk and memory based systems, like Hadoop and Spark, for storing massive amounts of data and various tools for dissecting datasets and correlating them, that makes it easier to create applications that use data and predictive and prescriptive algorithms. It is precisely analogous to the difference between the Google Parallel File System, and its follow-on, Colossus, and the Gmail and other Google App components that have ridden atop them for the past decade and which, by the way, have a fair amount of machine learning algorithms behind them to process spam and do other functions.
“Our DNA is deeply technical, but our job is to make the underlying technology disappear,” says Nguyen. “The problem with big data as an industry is that the conversation has been too much about the infrastructure. It is necessary, but it is not sufficient to realize the value. In the past five years, when the CIO has been asked by the CEO what the company is doing with its $5 million Hadoop cluster, the answer has been that they are doing various ETLs. The value of this Hadoop cluster is to be able to connect to it intuitively, to make it easier than an Excel spreadsheet.”
As an example, Nguyen fired up a graphical user interface called Narratives that is part of the Adatao stack, and used it to query a database from the US Department of Transportation that included all of the data relating to flights in the country for the past twenty years. This data was stored in a Spark database with 1.24 million rows, and typed in a simple query in the toolbar: Show relationship between day of the week and flight delays. And as fast as a blink, the Adatao tool fired off a query to a Spark cluster running on the Amazon Web Services public cloud sitting underneath the Adatao framework and showed the answer that we predicted, which is that Friday is indeed (from our personal experience) the worst day to fly and that Thursday is not much better:
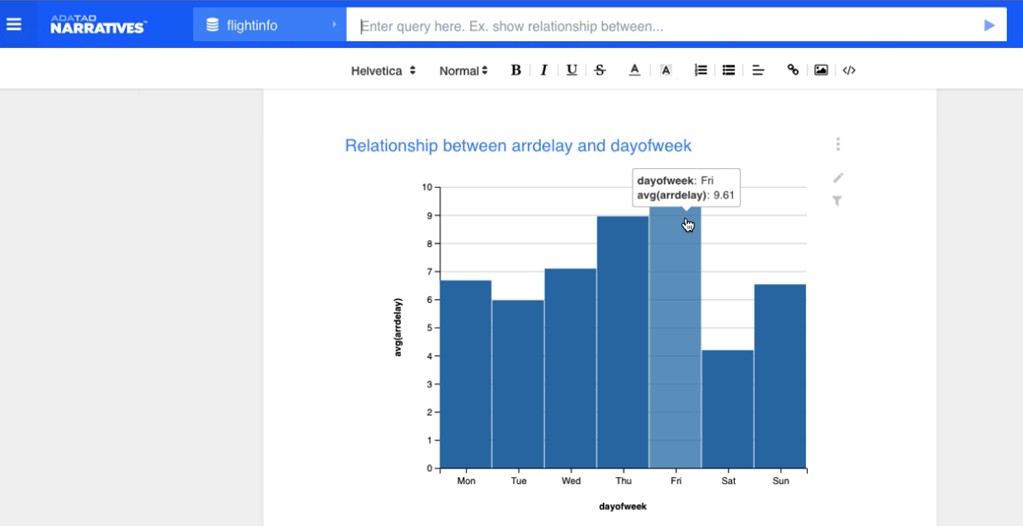
Nguyen says that this demo ran on AWS EC2 compute instances with a lot of RAM, with the raw data stored in the Hadoop Distributed File System before it is sucked up into main memory with the Spark add-on. He also says that with memory costing something on the order of $3 per GB that it is not uncommon for companies to spend $5 million for a cluster with petabyte-scale main memory these days, with memory comprising the bulk of that cost. This is one of the reasons why Nguyen and his team at Adatao have been working with the Spark community and contributing code to the project, which came out of Berkeley’s AMPLab (just like the Mesos cluster management system traces its roots to there).
The Tao Of Data
The Adatao stack has a number of different components, and it starts with an open source project called Distributed Data Frame, which is analogous to Google’s own BigTable in that it presents data stored in a massive file system as one giant table and allows so-called big compute frameworks like MapReduce, Spark, and others to distribute analytic compute against that data. Distribute Data Frame is open source, and the idea is to have a plug-in architecture much like the open source MySQL relational database has, allowing for different storage engines to be slid into the database without changing the data access layers or the applications that run against MySQL. Adatao has implemented this framework atop Spark for its own stack and has hooks for Java, R, and Python applications, but other compute and storage engines are possible and other programming languages are also supported, such as Scala:

The Adatao stack can also ride atop Facebook’s Presto SQL interface for Hadoop, Cloudera’s Impala SQL layer for Hadoop, and the Flink alternative to MapReduce and Spark that has been put out by Data Artisans. Data can be stored in Hadoop using HDFS or Cassandra or other NoSQL datastores, and Amazon’s Redshift data warehouse and various relational databases and SAP’s HANA in-memory database are also supported as sources for data that feed into this Distributed Data Frame table format. The Adatao stack assumes that all of this software is running on X86 hardware, but it also expects to see application accelerators and supports dispatching work to Nvidia Tesla GPU coprocessors, particularly for machine learning algorithms.
The Predictive Analytics Server, also called PredictiveEngine in some of the company’s documentation and also known as pAnalytics before Adatao dropped out of stealth, is written in Java and it is not open source. This is the key part of the Adatao stack, which allows end users to link to multiple datasets stored in the framework table, collaborate using different access methods in different programming languages on the same dataset, and as the name suggests, is stuffed with predictive analytics APIs to apply machine learning algorithms to these datasets.
Above this in the stack is the AppBuilder, which was formerly called pInsights and which has its back-end written in Java and its front-end written in JavaScript. It is analogous to an integrated development environment such as Microsoft’s Visual Studio or the open source Eclipse. AppBuilder includes dashboards – all business intelligence software does – as well as that text-driven interface we saw in action above called Narratives. R Studio, which is a popular IDE for programming in the R statistical programming language, also snaps into AppBuilder. Adatao is also working on something called BigR, which is in beta testing still, that allows for the construction and deployment of predictive models in R across an underlying cluster. (This is the kind of thing that Revolution Analytics, which is now part of Microsoft, also created.)
The Adatao tools have been in beta testing by dozens of customers – most of whom will not talk about how they are using it, as is generally the case with large enterprises. Chinese infrastructure supplier Huawei Technologies has licensed the Adatao tools to provide a tool to its telecom equipment customers to help them identify customers who are abusing promotional campaigns aimed at new rather than established mobile phone users. Another telco is using Adatao to analyze customer experience, correlating network performance data with call center data and tech support call data; this telco is also using it to do predictive ad targeting, product recommendations, and churn analysis and prevention. Other potential uses of the tool are the usual suspects for predictive analytics and machine learning. Predictive maintenance for heavy equipment manufacturers and outpatient predictive care based on emergency room and hospitalization records sprang to Nguyen’s mind immediately. Real-time, ad-hoc data exploration of operational data across all businesses is an obvious target, too.
The analytics stack from Adatao is available now, and while Nguyen was not comfortable giving out list pricing for his wares, he provided The Next Platform with some guidance on what it costs. AppBuilder has a per-seat pricing model and costs on the order of thousands of dollars per seat per year. The PredictiveEngine framework uses per-core pricing on the clusters where it runs, and it costs in the low thousands of dollars per core per year.
Adatao was founded in 2012, and received its Series A funding of $13 million back in August 2014. Andreessen Horowitz, Bloomberg Beta, and Lightspeed Venture Partners all kicked in the dough.

SambaNova Pits LLM Collective Against Monolithic AI Models
There is more than one way to get to a large language model with over 1 trillion parameters that can do lots of different things and enterprises can use to create AI training and inference infrastructure to extend and enrich their thousands of applications. One is to take a big …
Google Says The SOC Is The New Motherboard
For two decades now, Google has demonstrated perhaps more than any other company that the datacenter is the new computer, what the search engine giant called a “warehouse-scale machine” way back in 2009 with a paper written by Urs Hölzle, who was and still is senior vice president for Technical …

It Takes Geological Patience To Change Datacenter Storage
Moving from an HPC center or a hyperscaler to work on enterprise software has to be a frustrating experience. In the HPC and hyperscaler world, when you need to deal with a problem, it is usually one of scale or performance – or both – and you have to solve …
This is an interesting platform, Ive seen and worked with more than one middleware platform, but this is the first ive seen integrate deep learning. Do you know if the deep learning algorithm uses trained or untrained approach to be able to handle business data? or is there more than one engine used for this platform?
Ryan, my apologies for the very late response as I didn’t see this until now.
By using the DDF (http://ddf.io) data-integration layer, we built Adatao to be cross-engine, including first-class support for Spark, Flink, Cassandra, RDBMS, etc. Deep Learning then is an engine-implementation below DDF, in the current execution, is Spark and Tachyon-based. You can see our recent talk at Strata Hadoop in NYC on this topic here: http://conferences.oreilly.com/strata/big-data-conference-ny-2015/public/schedule/detail/43484 and slide deck here: http://www.slideshare.net/adatao/firstever-scalable-distributed-deep-learning-architecture-using-spark-tachyon.
Ping me at ctn@ if you have further questions.