

System reliability for large machines, including the coming cadre of pre-exascale supercomputers, which are due to start coming online in 2016, is becoming an increasingly important talking point since the addition of ever more densely-packed components in a system means frequency and compounded severity of errors and faults will be in lockstep with size.
Accordingly, there has been an uptick in research around the reliability of existing DRAM and SRAM technologies, as well as speculation about the role future stacked memory and NVRAM will play in creating more reliable large-scale systems. What is being found is that there is a good, bad, and ugly side to the memory technology in place with systems today—and the ugliest of those angles is enough to necessitate a complete rethink of memory for big machines.
A recent research effort using two large supercomputers, the Hopper machine at NERSC and the Cielo supercomputer at Los Alamos National Lab (which we talked about in other memory terms here) looked at memory-related reliability problems across time, device type, and vendor. Based on memory reliability research for these systems across three years of data, one of the lead researchers on the project, Dr. John Shalf, told The Next Platform that memory errors and faults pose significant limitations on large-scale machines going forward, but in the interim, there are some critical points the industry is getting wrong when it comes to evaluating the significance of memory errors.
“There have been a number of studies recently that say the sky is falling because the prediction models are based on error rates, but in fact, there are a lot of things that can be done about these errors. Studies that make predictions based on measured error rates are giving everyone the impression that there is a dramatic problem here because they are not looking at the fault rates—that’s the real starting place,” says Shalf.
Luckily, he says the models for testing and predicting the performance of memory tiers are solid, which means that both system integrators and chip designers have a good handle on where, why, and how often memory errors can occur. From that point, it’s just a matter of engineering to add more features to SRAM arrays on the chip to achieve error targets or for DRAM vendors to track potential weak spots and address them across a line or product range. “All of the vendors have a pretty extensive bag of tricks they can pull from and apply to achieve a target error rate,” Shalf explained to The Next Platform. “In other words, if their models for hitting desirable error rates is solid, there is a way to fix these issues, even if doing so is massively expensive, which it is.” But the price for these errors paid on the system end, especially for silent errors or those that require an entire node, or worse, job, to be shut down come with their own enormous costs as well.
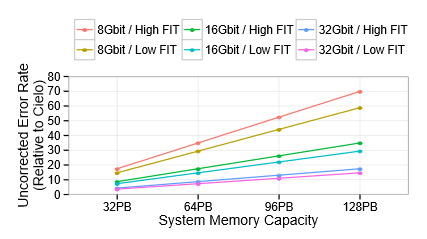
So, with the good news being that there are reliable models for evaluating memory errors and faults, let’s dig into the bad—and ugly news here. “Looking at the underlying fault rates for DRAM, we did find some cause for concern. If you look at the JEDEC roadmap and timelines for DDR4, the trends in terms of fault rates on DRAM is matching out model, but the total amount of discrete DRAM expected for an exascale system is extremely large, and the fault rates we project for how those get converted into errors tells us that the technology for correcting those errors is not sufficient.” The fact is, DDR does not have anything on the roadmap to deal with these issues and for vendors to get past this, it will mean added expense at the end, which is then passed down the line.
The other bad and ugly news that the team found is that there is significant variability between the vendors. “The incidence of these errors varied widely, depending on which vendor the memory came from, with the unnamed Vendor A being 10X less reliable than the others.” While Shalf noted that this was a tightly guarded secret—the anonymity of the vendors was cooked into the tests from the beginning, it does put added pressure on system integrators to run their models and be quick to spot these issues or face having to do a full replace.
It is tempting to go through and find which memory vendors were part of the Cielo and Hopper systems, but Shalf said that there were multiple vendors’ parts used in each of the systems, which means discovering this isn’t possible. The main takeaway, however, is that when system integrators like Cray, whom Shalf says does an excellent job of running these models and tracking in detail how memory SKUs and product lines behave in their machines.
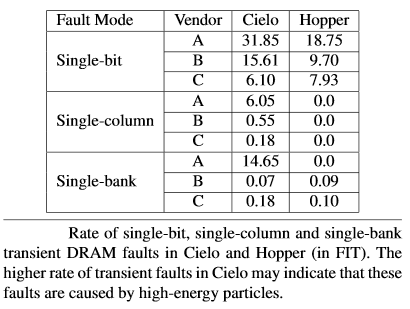 “The system integrators keep information that is tracked across all the memory vendors. It’s part of their internal secret sauce, which is why you need an integrator—it’s like having a contractor on the construction site who can see the big picture,” Shalf explained. “But still, any individual manufacturer can have a bad day where some parts that one day just don’t come off very well. It’s not a matter of saying there’s a clear case that Vendor A is better than Vendor B in what we’ve done here, even if we were able to see who they were. The point is, the system integrators have this data and can choose lots based on this information and find these things out over time.”
“The system integrators keep information that is tracked across all the memory vendors. It’s part of their internal secret sauce, which is why you need an integrator—it’s like having a contractor on the construction site who can see the big picture,” Shalf explained. “But still, any individual manufacturer can have a bad day where some parts that one day just don’t come off very well. It’s not a matter of saying there’s a clear case that Vendor A is better than Vendor B in what we’ve done here, even if we were able to see who they were. The point is, the system integrators have this data and can choose lots based on this information and find these things out over time.”
As Shalf concluded, “reliability will continue to be a significant challenge in the years ahead. Understanding the nature of faults experienced in practice can benefit all stakeholders, including processor and system architects, data center operators, and even application writers in the quest to design more resilient large-scale datacenters and systems.”
We are not in the business of summarizing deep academic articles, but definitely wanted a pointer to this research since HPC systems will be saddled with much of the technology in question here in the years to come. With so little available about stacked memory and forthcoming memory technologies, having a balanced set of expectations about fault, error, and realistic assessments of what this means for the upcoming pre-exascale systems is important to share.

Be the first to comment