

In our coverage of the string of next-generation HPC systems, we have talked about the big changes on the programming, memory, and network horizons, but there is one potentially disruptive change on the way for storage—one that could tear down existing paradigms, including the concept of time-tested parallel file systems.
The shift starts with a new layer of storage that is set to appear on the upcoming CORAL supercomputers, which is intended to serve as an I/O enhancement called a burst buffer. While the national labs are expecting major improvements for things like checkpointing, for instance, those petabytes of NVRAM in the CORAL machines could serve a much larger function following some clever software interlacing to create a new approach to using multiple tiers of storage for far more than just I/O.
As we have detailed in the past, Los Alamos National Laboratory was the originator of the burst buffer concept to boost I/O on large supercomputers, but the plan was always to see this storage tier as something that could tie off other data movement bottlenecks and find real use within applications. Beyond serving as a high-speed, high-capacity dump for checkpoint data, that layer of NVRAM could potentially serve the same functions—and go far beyond—traditional file systems, even on a machine like the Trinity supercomputer, which will have 2 PB to 3 PB of main memory, 7 PB of NVRAM to support the burst buffer, and 82 PB of disk capacity. While that is going to take quite a bit of development with the upcoming sets of pre-exascale machines outfitted with this NVRAM layer, Gary Grider, head of high performance computing at Los Alamos, says that exascale systems simply will not use file systems at all.
What is needed is a new storage abstraction layer can allow the same storage to be viewed by a diversity of namespace abstractions. In plain English, a software framework that can support that layer of NVRAM like a “first class citizen” in the storage hierarchy, Grider tells The Next Platform. To do this, such an abstraction layer for generalizing storage options has to provide several services that users rely on currently, including transactional support, reliability, availability, and data protection).
“With storage like that provided by NVRAM, most people won’t want to access it as files, they are going to want to access it as part of the application–as data structures that simply happen to live in persistent storage as opposed to in memory. So what we are thinking about now are the multitude of ways people will want to view that piece of in-system storage. It’s a matter of abstracting the storage in such a way that lots of different namespaces can use it while providing the semantics they expect or need.”
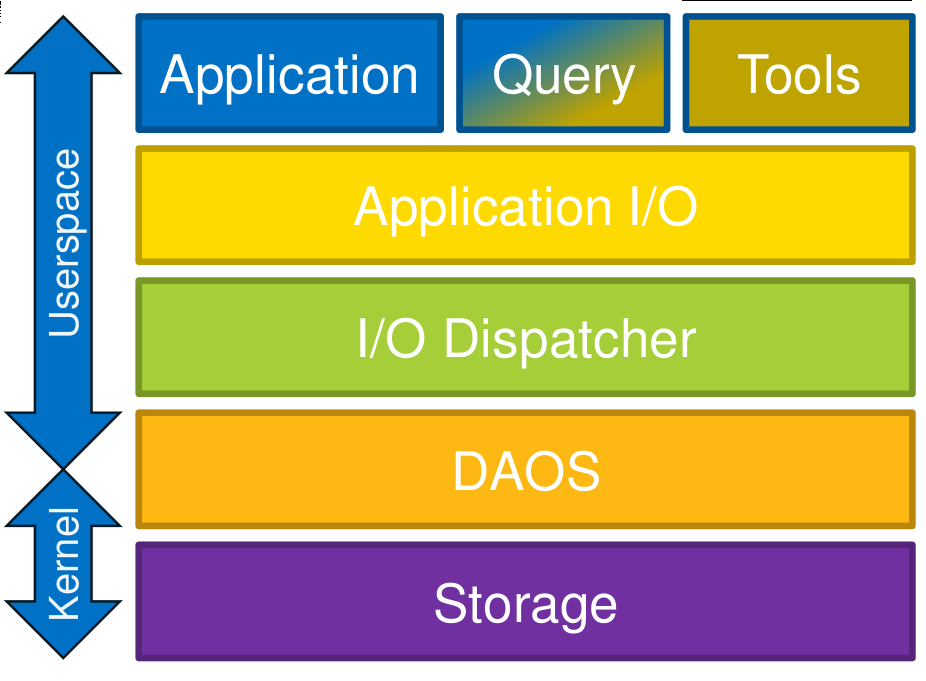 In short, this introduction of NVRAM as a real first-class citizen within the system’s storage hierarchy means that file systems could very well fall out of favor. The outcome of this thinking is found in the DAOS project, which is part of the Fast Forward Storage program and funding and which is a priority for teams working on it at Intel, Los Alamos, and other centers.
In short, this introduction of NVRAM as a real first-class citizen within the system’s storage hierarchy means that file systems could very well fall out of favor. The outcome of this thinking is found in the DAOS project, which is part of the Fast Forward Storage program and funding and which is a priority for teams working on it at Intel, Los Alamos, and other centers.
When it is finally realized in practice, DAOS can allow multi-use of the same storage by providing that very low-level abstraction for talking to each layer of storage as well as the capacity layer that sits below it in a way that allows users to map any kind of namespace they might desire onto it. For example, a user might want to make something look like a file, so she would ask DAOS to create the logical container to make it look as such. In theory too, DAOS can make something look like an HDF5 container and also possible to have DAOS treat a specific piece of that NVRAM layer or disk in that manner. In the broader world beyond exascale supercomputers, in cloud environments, it could be used as space for Memchached memory caching, where users want to build a transparent caching layer where they can put all their indexes in memory. It is just a matter of “asking” DAOS to make a layer of storage appear a certain way to allow several uses for one (or more) layers of storage.
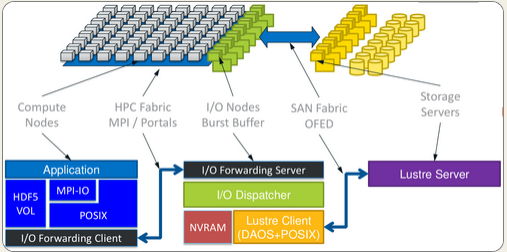 This frees the concept of storage from traditional strictures; DAOS can be used by an application programmer to create a place to store arrays, to write files to, to be used for scratch like Memcached—the idea is that you don’t necessarily want every vendor who sells a machine with this layer of storage to provide a different interface to access all of that, you want a common interface so that middleware and programing modelers and others can write to the DAOS abstraction and make that storage look like anything they want it to be.
This frees the concept of storage from traditional strictures; DAOS can be used by an application programmer to create a place to store arrays, to write files to, to be used for scratch like Memcached—the idea is that you don’t necessarily want every vendor who sells a machine with this layer of storage to provide a different interface to access all of that, you want a common interface so that middleware and programing modelers and others can write to the DAOS abstraction and make that storage look like anything they want it to be.
While there are multiple layers of complexity to DAOS, the bare concept boils down to the very simple concept of namespaces, which are essentially just clever ways for programmers to remember where things are. If the namespace becomes a layer that sits on top of multiple types of hardware (disk or NVRAM, for example) the same concept loops through and DAOS can let the application developer choose what hardware the namespace rests on. This sounds simple in theory, but naturally, there is a great deal of work to be done yet to make this abstraction layer clean and standard so that vendors have something to standardize on (note again that Intel is heavily involved in this).
“It would be nice for an application programmer to be able to code like they think. For instance, to say, ‘this is simulation 47 and here are the pressure and temperature factors but all of that needs to be squashed down into a file where all the extra information has to be dropped out. It would be nice if that programmer could come back later and ask the storage system to pull all the simulations that were run where pressures were over a certain amount and other properties met other certain criteria’ and then it starts to sound like a database.”
“This is where databases and file systems start to mesh. Databases are really just namespaces in essence, just another way to name something with different properties. We want to allow application programmers to not have to convert things into some artifact called a file system in a completely different namespace just because that’s the way file systems we made. And to do that, we need something that is flexible, that lets them choose a namespace to stick on top of that storage that can support those artifacts and plenty of new ones.”
It is at this point that one can very easily start to see how the notion of file systems as the standard way of making use of storage starts to break down. But again, there are big roadblocks in the way of making something like this a de facto standard, in part because it will involve some ripping and replacing of code. And for large-scale scientific codes, where DAOS will be put to the initial test, this is a significant undertaking.
Putting DAOS into play will mean more than just working out the abstraction layers to get the functionality Grider and his team hopes for. This will add yet another layer of complexity for programmers on pre-exascale and exascale machines who already have quite full plates (as we discussed in depth in the context of programming the massive Summit HPC machine coming to Oak Ridge National Lab. Not only will these programmers be considering new levels of massive parallelism and heterogeneity, but now they will have to think through the multiple tiers of memory and how to best address these in the most efficient manner. DAOS is set to help with this, but each application will need to be specifically tuned to make it work the way Grider and teams at Intel and elsewhere envision.
In fact, while application programmers are hard at work rewriting their codes to meet the multidimensional new needs for next-generation systems, these new ways of taking advantage of what DAOS adds to the I/O subsystem will be among the new things they code for. The problem is, for DAOS to become a reality at all it will mean rewriting applications, something that the big scientific code shops are already well aware of (and working toward) but that the rest of the world might not be ready to do.
As a side note to end, work on DAOS has been fed by the Department of Energy Fast Forward I/O storage program, which targets exascale computing research and development across the national labs and key vendors. If you’re looking for something that goes far deeper into the proposed functionality, there are some presentations and project documents from some of the key people behind DAOS at Intel, including Eric Barton, as well as materials from Grider at Los Alamos. And as another side ending item, you’ll notice from the materials above that Intel is involved, but this was not the original intention. At the beginning, Lustre startup Whamcloud won the I/O and storage contract (along with other companies, including the HDF Group, EMC for burst buffer projects, and Cray for scale-out storage research). With the Intel acquisition of Whamcloud, the Fast Forward I/O contract was renegotiated with Intel and DataDirect Networks both working on specific research and development areas.

Be the first to comment