

In the wake of today’s announcement of the codes selected to be tuned for the 2018 Summit supercomputer at Oak Ridge National Lab, questions around how application teams are thinking about the massive amount of memory across new tiers, the swapping out of PCIe for a new interconnect, and the pervasive GPUs were first to mind.
While there are new capabilities on this system in terms of potential performance and efficiency gains, some of the possibilities that have opened come with plenty of unknowns. For instance, the machine will feature some untested technologies in the way of non-volatile memory (NVRAM), the NVLink interconnect that will dramatically hasten communication between multiple GPUs and between the CPU, and an unfathomable (and as of yet non-public) number of cores on the Volta generation of Nvidia GPUs and next generation IBM Power9 processors. As one will quickly notice, this architecture is completely new–and based on a number of elements that do not even exist yet. So then, how are the first rounds of application teams considering their first steps?
Even with all of these fresh features, one of the things programmers for early Summit use seem most excited about is simply having more memory, Dr. Tjerk Straatsma, group lead for the scientific computing division at ORNL, told The Next Platform. For large supercomputing centers, all the cores in the world are useless after a certain point without sufficient memory, as we just described today in the context of limitations at Los Alamos National Lab and their weapons stockpile simulations.
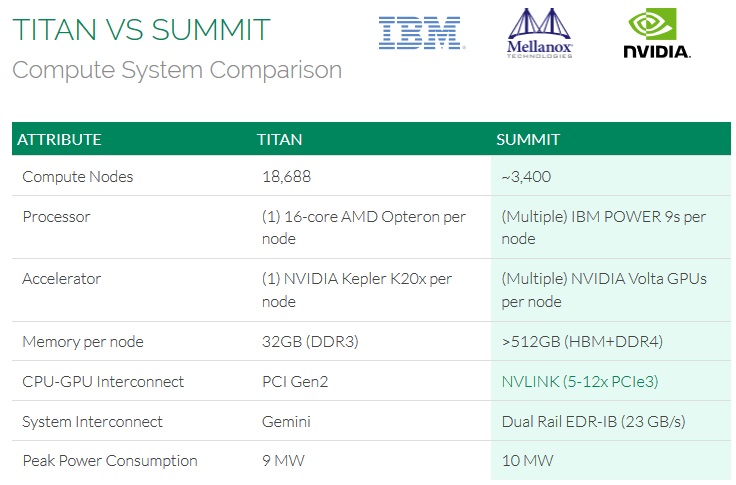
The same issue has been prevalent at Oak Ridge National Lab on the top-tier Titan system where some codes, particularly important research applications in computational chemistry, have to be creatively and inefficiently carved into pieces to run due to memory constraints. This carving process and the replicated data structures that come with it will go away with Summit, where applications will have half a terabyte per node. What’s more important is that this is coherent memory that preserves the hierarchy, which means once the vendors and application teams work together to figure out a way to make this work properly (remember, none of the hardware and little of the software for this has actually been built yet) it means that there will be memory that sits next to the GPUs, more that’s hooked closer to the DDR4 memory, and, just to make things even more interesting, additional NVRAM on the nodes as well.
The question might no longer be whether there’s enough memory for an application to hum, but rather, how the data structures are divvied up and using what methods. The point is, the vendors and research labs have a great deal of work to do to help find a solution for how memory placements occur. Even with the NVLink to ship the data around and the improvements over PCIe that are implied there, the point of the system is to put the data where the compute is, whether that means CPU or GPU. It’s not just a matter of placing data closest to where it’s needed; there are still plenty of other aspects that go hand in hand there; for instance, the size of the data structures, how much is going to be in DDR, how much in the GPU, and so forth are all areas where the vendor and application teams will have to work together.
“With coherent, unified memory we don’t have to copy data any longer from one memory space to another. All of these units, whether GPU or CPU will have access to all the memory on the system. Now it’s just a matter of allocating memory for certain data structures as close to being used as possible.”
And here’s something interesting along those lines as a side note. There are plenty of codes that were listed in the announcement today that are not what we’ve traditionally considered as GPU superstars. In fact, Straatsma says that some of them have yet to be ported to run on GPUs at this point. The reason is not because they can’t benefit from the acceleration of those massive numbers of cores (we still don’t know how many will appear with the Volta GPUs, but it will probably make our brains hurt) but because the data movement penalty over PCI was just too hefty to bear. With that bottleneck lifted with NVLink, new worlds open in terms of actually making efficient use of the high performance GPUs.
“A lot of codes that currently have problems running on the GPU do because the PCIe bus is so slow and the memory on the GPU is so small. They have to transfer a lot of data to the GPU, transfer it back—it’s all expensive and allow one to see the benefit of the GPU. That will be significantly different with this architecture and the range of applications that can use the GPU will be much bigger.”
Straatsma says that one of the things the application teams are excited about beyond the massive memory space is the fact that they are working with far fewer nodes—the difference between over 18,000 to just under 3500 means dramatic simplification of some of the high level parallelism, although there are some new challenges ahead for those users whose codes have not been ported to run on GPUs for Titan previously, which is true for some of the chemistry codes on the list.
For these users who have not climbed aboard the GPU express, it’s time to get used to running their applications on them since it is no longer a choice. Before, with Titan, not all of the codes used accelerators, but Straatsma says that with 90% of the floating point value coming from high core-count GPUs, all applications will need to adopt them into their codes. Whether this means poring through the codes and finding the small slices that perform poorly and tuning there or completely rewriting large swaths of million-plus line code will depend on the application, but all the teams, with help from Nvidia, have a great deal of work to do. “The goal for all of the applications on this early list is that they can use 20% of the machine effectively. That’s really our main metric and this means using the GPUs.”
There are also codes in that list that run almost exclusively on the GPUs, including the plasma physics codes—this will be more a tuning and optimization effort for them rather than a refactoring of the code or restructuring as it will be with some others. “We are confident that with all or almost all we can be successful, but some will be easier to work with than others.”
The most work that will need to be done is in the area of relativistic chemistry code, which only runs in parallel using MPI, has a lot of replicated data structured, and there is a lot of software infrastructure that will need to be built to support it. But the main module that’s being targeted here is the same as other codes that have been successfully primed for GPUs, so there is a methodology in place that can be carried over. Now, with more memory and faster data access it will be more suitable, but this is representative of important, but troublesome applications that can scale well, but at this point, can’t fully take advantage of the system’s massive floating point capabilities from the GPU cores.
“We looked at two things when we evaluated all of these software project proposals. First, is it technically feasible and second, how much effort will it take and does the team, between us and the vendors, have what it takes to make it happen.”
One the application areas IBM is interested in is deep learning and large-scale analytics, which Straatsma expects will drive some of the new (from the ground-up) applications that Summit will run in the future. “An architecture such as Summit lends itself well to these, especially with the addition of non-volatile memory on this machine.”
The non-volatile memory he refers to is something that is greatly anticipated in this and other future systems. NVRAM represents some new possibilities beyond its initial often-discussed purpose as a burst buffer to keep healthy I/O on what might otherwise be a bottlenecked system. Since I/O is slow (and certainly can’t be for large scientific simulations) it has to be handled in bursts. Prior to burst buffer technology, users would have to wait until this burst cleared out to continue, but NVRAM can take the entire dump of that data and slowly slough it off to the file system.
On the data applications side, the NVRAM can be used to store large databases that are static during analysis. In essence, these can be loaded and run the analysis codes against them, using NVRAM as storage. There has also been discussion about the use of NVRAM for resiliency; if crucial data for the application on NVRAM, if a node dies but is still accessible through the network and the NIC to the NVRAM, it would be possible to quickly ship the data to another node and be up and running without halting the simulation. Again, this is still completely new—but the potential applications (and we have a long piece about NVRAM and what it means for the future later today) are growing.
“I would think that most applications we are going to run at first won’t use the NVRAM, it will be used to make I/O faster, but we’re giving this a lot thought,” said Straatsma.
For a full list of the codes that were selected as part of the Center for Accelerated Applications (CAAR) can be found here https://www.olcf.ornl.gov/caar/

Crafting A DGX-Alike AI Server Out Of AMD GPUs And PCI Switches
Not everybody can afford an Nvidia DGX AI server loaded up with the latest “Hopper” H100 GPU accelerators or even one of its many clones available from the OEMs and ODMs of the world. And even if they can afford this Escalade of AI processing, that does not mean for …

IBM Chips In To Drive 2 Nanometer Semiconductor Manufacturing
Big Blue got out of the chip foundry business when it sold off its IBM Microelectronics division to GlobalFoundries, itself a spinout of AMD, in 2014. The hope, no doubt, was that IBM could get out of investing in its foundries, which were not high volume facilities but expensive nonetheless, …

Where To Park Your AI Cluster Is As Important As Procuring It
When we think about high performance computing, it is often in the context of liquid-cooled systems deployed in facilities specifically designed to accommodate their power and thermal requirements. With artificial intelligence, things can get tricky. While the systems themselves are powered by many of the same CPUs, GPUs, and NICs, …
This represents a very unsettling aspect of going into exascale–the gap between accessible computing (the 99% of HPC users) and leadership-scale computing is going to expand to a point where users are either on the wagon or they’re not. There will be no middle ground.
What happens to the vast majority of HPC users who are using codes that aren’t backed by dedicated scientific software developers? Will they simply be stuck at a performance level where die shrinks stopped being physically possible?
And considering the fact that only ~50% of Titan’s current load even uses GPUs even after extensive application readiness programs and training by ORNL, what happens to the other 50% of cycles when Summit replaces Titan? Ideally some of the “lost” 50% will be brought on the wagon by these new application readiness efforts, but will the remainder be left out in the cold and told to look elsewhere?