
The hyperscale giants can’t wait for the IT industry to invent the technologies that they need for their own applications, but when the time is right an open source alternative grows up and out enough, they will often make the jump from their own software to another stack. This is precisely what is underway right now at web portal Yahoo as the company shifts from homegrown object storage to what will soon be an exascale-class system based on open source Ceph, a kind of Swiss army knife of storage.
Such jumps are not common because hyperscale companies tend to be pushing out beyond the scale limits of any technology that they deploy, open source or otherwise, and usually open source. But it does happen. For instance, as The Next Platform discussed earlier this week, media giant Netflix has been using a custom version of the Cassandra NoSQL database as the back-end for controlling its media streaming services and user interaction, and only last fall did it port over to a commercial-grade variant of Cassandra from DataStax. Yahoo is making a bigger leap than this by moving from its homegrown MObStor object storage system for unstructured data to Ceph, but it is one that it has made after careful consideration, Brad McMillen, vice president of architecture at Yahoo, tells The Next Platform.
It All Starts With Cat Photos
Yahoo was one of the innovators in object storage at scale, along with Facebook and its Haystack system and Amazon and its S3 system, and the Mosso Cloud Files system that was the foundation for Rackspace Hosting’s Swift object storage, now part of the OpenStack cloud controller. In the case of Yahoo and Facebook, it was the storing of hundreds of millions of user photos, taking up petabytes of capacity, that caused so much grief that both companies invented their own systems to more efficiently store those photos. Amazon and Rackspace wanted object storage as part of their public clouds, assuming that customers creating cloudy applications would also want to weave lots of rich media into them.
All of the object storage systems mentioned above – Haystack, MObStor, S3, and Cloud Files/Swift – were created because regular storage arrays with file systems had a tremendous amount of overhead due to the metadata that was needed to keep track of where objects were stored in their clusters. Object storage just ignores a file system and puts everything in one bucket, using a key such as the file name or a web address to locate it in the cluster. This takes a lot less metadata because there is no file system to contend with.
The original Yahoo Photos service from more than a decade ago had a special storage system tuned for unstructured data, and it was followed up by a more sophisticated and pervasively used object storage system created by Yahoo called MObStor, which Yahoo first talked about publicly back in the summer of 2009. Yahoo’s acquisition of photo sharing site Flickr in 2005 greatly exacerbated its need for a technology like object storage, but MObStor is where Yahoo applications dump JavaScript and HTML code as well as rich media. Yahoo’s engineers gave an update in the summer of 2010 on MObStor, which was fairly new then, and in six months the capacity on the system had grown by a factor of 4X. That was also when Yahoo revealed it was working on and patenting a system called Direct Object Repository Architecture (DORA), a new back-end for MObStor called that is a clustered object storage system that in many respects resembles Ceph. MObStor is the interface into the DORA back-end system that programmers at Yahoo write to when they need to save stuff that is unstructured, like photos and videos and other tidbits of data. The DORA setup was designed to run on commodity hardware as well as storage appliances, and Yahoo is purposefully vague about what that means, but the idea was that the DORA backend had features that allowed Yahoo to do object storage on cheaper systems.
We will be operating at the hundreds of petabytes scale, and I don’t know anybody else in the Ceph community who will be doing that. If we are not the largest, then we are one of the largest production users. And we are probably going to find our fair share of scale issues. You just see things at Yahoo scale that you don’t see at traditional scale.
After some nudging McMillen said that across all of Yahoo’s services and datacenters, it has exabyte-scale storage when you add up object, block, and file storage together. In a blog post that discussed Yahoo’s move from MObStor to Ceph for its Flickr photo-sharing service, the company said that it have over 250 billion objects and around 500 PB of photos, videos, emails, and blog posts that it stores for its users, and that this object storage is growing at 20 percent to 25 percent annually.
MObStor is “feature complete” according to McMillen and is widely deployed at Yahoo. So why is Yahoo investing in a different technology if MObStor is widely used and well regarded? It comes down to money, one way or the other.
For one thing, MObStor is a closed-source program and that means that Yahoo has to create, extend, and support the tool all by its lonesome. The widespread uptake of the Hadoop data analytics platform, which was created by Yahoo, open sourced, and now has a deep bench of software engineers improving at all layers of that platform demonstrates the value of community development.
“I would say that the biggest reason for moving to Ceph is that we just wanted lower storage costs,” explains McMillen. “Our storage has grown a lot and we are looking to squeeze costs as much as possible and have as many options as possible instead of being wedded to one system, one technology, and one hardware architecture.”
The original MObStor object storage was designed to run atop storage arrays that had RAID data protection activated to keep the files safe. With DORA, Yahoo added the option to replicate data across arrays in a storage cluster. RAID and replication carry a pretty hefty overhead, and McMillen did not want to give any specifics about how MObStor compared to Ceph in this regard. But he did say that with the traditional object storage systems that Yahoo examined, the overhead for three-way replication is 200 percent, and with the erasure coding techniques used in Ceph and other object storage, you can squeeze it down to 40 percent to 60 percent overhead. With the tunings that Yahoo has done on Ceph, McMillen says it is closer to 40 percent overhead with erasure coding protection compared to just storing it raw. And that means Yahoo can store the same capacity in Ceph at around half the cost of doing it with a traditional object store with triplicate copies.
The MObStor/DORA setup did not support erasure coding, and Yahoo would have had to graft it onto the system, which meant a great deal of development and testing effort. Ceph, on the other hand, is designed for exascale deployments and has erasure coding techniques for protecting data built in. (With erasure coding, a bit of unstructured data is broken up and spread across the storage and if a bit of it is lost, the erasure algorithms can be used to recreate the lost data.)
Cloud Object Store
The new Ceph-based system that Yahoo is deploying is called Cloud Object Store, and it has been in trials since last fall at the Flickr section of the Yahoo stack. At the moment, Flickr has “multiple petabytes” of Ceph capacity under management, and over the course of this year Yahoo plans to increase that by a factor of ten to “low hundreds of petabytes,” according to McMillen, as it rolls out its Ceph-based cloud object storage underneath Flickr, Yahoo Mail, and Tumblr. (McMillen says that Flickr has a lot more storage than this amount and that pieces of it will remain in MObStor for some time.)
Yahoo looked at Swift and Gluster file systems as well as a few proprietary alternatives in its search for a new object storage system, and ultimately it zeroed in on Ceph. For one thing, McMillen says that Ceph was interesting in that it supported both object and block storage on the same systems – and someday (hopefully) file system storage, if the Ceph community ever works the kinks out.
“Not all of Yahoo’s storage is suitable for object storage, but a lot of it is,” says McMillen. “We are using block storage but it is not as far along as object storage. One of the things we like about Ceph, besides that it has lower costs because of the erasure coding and that it is an open source project that is picking up speed in the developer community, is that it is a single storage system that does block and object. So instead of having a separate storage system for block and object, we can master one technology stack and use it in two ways. And if Ceph had a file system that was stable, we would definitely be using that today.”
The Ceph community – backed by Red Hat, which acquired Ceph steward Inktank a year ago for $175 million – is working on that.
While Ceph can be scaled in a single cluster to an exabyte-class storage system, McMillen says that Yahoo is implementing Ceph in a pod structure that will enable more predictable performance and better fault isolation than a single cluster would. Here’s what it looks like:
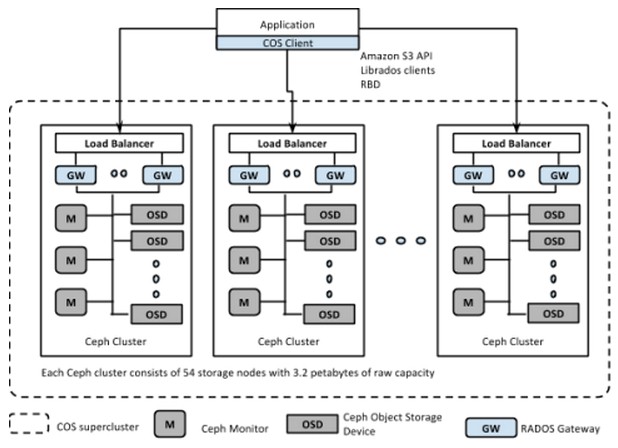
In the Yahoo Cloud Object Store, each node (called an Object Storage Device) has 60 TB of storage and is based on an X86 server. Yahoo has tried configurations ranging from 12 to 72 drives per node, and is not divulging its hardware configurations for its COS service. Each cluster has 54 of these nodes for a total capacity of 3.2 PB. To scale out the service, Yahoo replicates these pods and uses a hashing algorithm to break the unstructured data across the pods and across the nodes using erasure coding.
Depending on the application, Yahoo is using normal hard drives or disks that employ shingled magnetic recording (SMR) techniques, which have different capacities and costs; SSDs are also deployed in the COS service to provide higher I/O rates.
Yahoo is using 8/3 erasure coding on its variant of Ceph, which means three of eight servers or drives on which an object is sharded can fail and it will still be accessible. This is the normal level of encoding used in Ceph. But Yahoo has cooked up an 11/3 erasure coding variant for Ceph, which means three out of eleven drives or servers can fail and, importantly, can reduce average read latencies by 40 percent. (Yahoo plans to donate this improvement back to the Ceph community, by the way, and it could make its way into the “Hammer” release of the code, according to McMillen.) The company has done a bunch of other tweaks to squeeze more performance out of Ceph, as this chart shows:
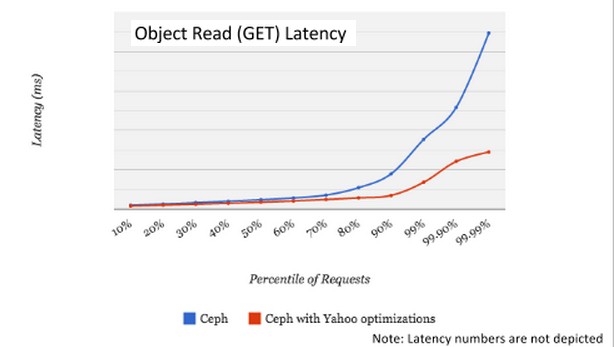
In addition to this erasure coding change, Yahoo has come up with a way to shard the bucket index, which is an index that keeps track of the objects stored in a bucket. (That’s an Amazon term for a unit of object storage capacity.) Normal Ceph implements the bucket index on a single server nodes, but Yahoo’s engineers have figured out how to shard it and spread it across multiple nodes for high availability and performance improvements. Yahoo has also cooked up a way to throttle back the rate at which data recovery is done when there is a disk or server failure, improving latencies during recovery by about 60 percent.
At the moment, Yahoo is self-supporting its implementation of Ceph, but McMillen says that the company has a good relationship with Red Hat and is not against the idea of using Red Hat for some technical support. But Yahoo is on the bleeding edge of hyperscale here with Ceph, and maybe self-support is the only option for now.
“We will be operating at the hundreds of petabytes scale, and I don’t know anybody else in the Ceph community who will be doing that,” says McMillen. “If we are not the largest, then we are one of the largest production users. And we are probably going to find our fair share of scale issues. You just see things at Yahoo scale that you don’t see at traditional scale. We are committed to working through all of those issues, and I think the community is going to benefit from all of that.”

How OpenStack Lassoes Yahoo’s 4 Million Server Cores
As one of the first hyperscalers in the world, Yahoo, part of the Oath conglomerate that also includes AOL and that is owned by telecom giant Verizon, knows a thing or two about running applications at extreme scale. Back in the day, this was done by hand, but these days, …

How Yahoo’s Internal Hadoop Cluster Does Double-Duty on Deep Learning
Five years ago, many bleeding edge IT shops had either implemented a Hadoop cluster for production use or at least had a cluster set aside to explore the mysteries of MapReduce and the HDFS storage system. While it is not clear all these years later how many ultra-scale production Hadoop …

Hadoop, Spark, Deep Learning Mesh on Single GPU Cluster
When it comes to leveraging existing Hadoop infrastructure to extend what is possible with large volumes of data and various applications, Yahoo is in a unique position–it has the data and just as important, it has the long history with Hadoop, MapReduce and other key tools in the open source …
The way I read the Yahoo blog posting is that they are using a 8:3 erasure code, but that on read they retrieve the orignal 8 chunks and the 3 parity chunks. Once they have 8/11 of these chunks they compute the object for the client. In this way 3/11 chunks can be more latent without affecting tail latency. This is subtlety different than using a 11:3 code, which wouldn’t require a code modification, Ceph supports any value of k or m for a erasure code profile.