

If you haven’t heard of Flink until now, get ready for the deluge. As one of a stream of Apache incubator-to-top-level projects turned commercial effort, the data processing engine’s promise is to deliver near-real time handling of data analytics in a much faster, more condensed, and memory-aware way than Hadoop or its in-memory predecessor, Spark, could do.
What really captured our attention, however, was the claim by Data Artisans, the company behind Flink, that the new tool can deliver 100X the speed of Hadoop with all the necessary programming APIs firmed up, including those for Java, Scala, and the coming promise of MPI. Further, the founders of the project, several of whom are now behind the Berlin-based Flink startup, are keen on showing how it can replace the in-memory and real-time processing power of Spark with many of the similar benefits and approaches thanks to its more sophisticated memory management, iterative processing, and optimizer capabilities.
But the question is, why does this matter so much when we are only just finally starting to see a broader range of Hadoop workloads in actual production in major enterprise settings? The quick answer is simply that real-time will matter more than ever, especially in the sweet spot for big companies analyzing mountains of consumer, web, sensor, and other information—not to mention those heavy-duty users who are employing Hadoop for mission-critical analysis. It certainly doesn’t hurt when the same engine can also do batch processing when required as well, as is the case with Flink. While each of the Hadoop vendors have snapped in tools to make real-time more of a reality on a platform that was never designed to do anything beyond batch jobs, with more deployments comes more demand for performance, which just spawns entirely new use cases for Hadoop and its in-memory brethren, Spark. And so the cycle goes.
From the outside, Flink does not look like anything more than just another member of that processing family inside an ever-expanding open source analytics toolchain. It’s in the same family as Hadoop and Spark (and others), but where does one tool begin and another end? Think of it this way: Flink can do what does Spark does in the streaming in-memory sense, what MapReduce does in the batch sense, but it can do it all with some memory management, built-in optimizer, and transformation kicks that might be just enough to upend the open source data processing hierarchy. How Flink gets adopted and commercialized is still an unknown.
Flink is a runtime system that is not so different from MapReduce or Spark (more on those differences coming) but there is not a storage system component. In short, Flink pulls data from its source (HDFS, S3, etc.) and processes it from there, which is similar to how MapReduce reads data from the file system or Spark—but these minute differences are where the real benefits lie.
As Data Artisans co-founder Kostas Tzoumas explains to The Next Platform: “Current engines for data processing are designed to perform their best in one of two cases: when the working set fits entirely in memory, or when the working set is too large to fit in memory. Flink’s runtime is designed to achieve the best of both worlds. Flink has great performance when the working set fits in memory, and is still be able to keep up very gracefully with “memory pressure” from large datasets that do not fit in memory, or from other cluster applications that run concurrently and consume memory.”
There are two ways in particular that Flink shines; in the way it handles iterative data processing (very important given its importance in many large scale analysis problems at the top of enterprise hit lists) as well as its memory management capabilities. It is in these two areas where the “100X faster than Hadoop” claim comes to bear and where Flink has credence as the next early-stage step for where existing Hadoop workloads could go. Unless, of course, it becomes part of the core of one or more of the Hadoop distributions—but we’ll save that bit of speculation for another time.
The value of high performance iterative data processing cannot be underestimated, especially as the number of clustering and graph-like algorithms expand in scope and purpose in the enterprise. But isn’t this kind of iterative stuff the magic that made Hadoop and, more recently, Spark, the darlings of the big data world? According to Robert Metzger, a founding member of the Flink project, there are some key differences in how these two existing frameworks tackle iterative processing. And Metzger says that Spark is inherently less efficient than Flink.
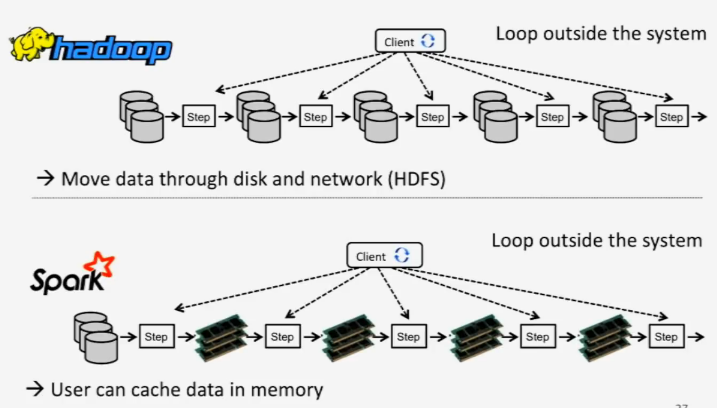
As shown above, with Hadoop, you read the data once, run the jobs, write those results, then read those results again from HDFS, then onto the next step. That’s great, but it’s very slow since it’s constantly going through disk. To get around those disk hurdles, Spark emerged and found a place in the ecosystem since it brought much faster in-memory processing for the same data. However, it is not without limitations because there are still cache steps between the iterations.
What Flink is doing instead is handling these steps with iteration operators. Tasks keep running for the iterations and are not being constantly re-deployed and re-read for each step. The caching and some underlying optimizations there are handled transparently within Flink, while handling a defined amount of the data in memory to avoid spilling into disk at undefined points as much as possible.
The way Flink handles memory is also part of that secret performance sauce. The need for super-efficient in-memory data processing is why Spark has become popular, but Flink’s founders have found a way to “take out the trash” of the memory management process. For a lot of data-intensive workloads, the garbage collector in the Java Virtual Machine (JVM) is kept constantly busy, which creates a bottleneck. Flink lightens the garbage collection overhead by managing all the memory inside the JVM, allocating specific portions for the user’s data, the network, and the operations. From the outset, Flink automatically allocates 70 percent of the free heap space. This means there’s a huge chunk of memory pre-assigned from the beginning, so all operators are getting a fixed amount of memory to operate on. When those are done, the memory gets handed back for the next round, meaning that in-memory operations are maximized.
Given that Flink was developed among database and distributed systems researchers, it is not surprising the early developers wanted to bring the best of both worlds to bear. Specifically, the teams looped in scalability and reliability benefits they saw in Hadoop and meshed those advantages with the various pipelining and query flexibility features of databases. While Hadoop is more flexible in that it is based on schema on read versus write (so data can be seen before processing), users still have to think a great deal about execution. With database systems, however, the focus is on the query instead.
Spark has what is called a resilient distributed dataset abstraction layer and while Flink does as well, there is a transformation layer that changes the performance profile. It offers users a transformation that turns that distributed dataset into a new, condensed dataset. Some of the transformations available within Flink’s DataSets transformations are traditional things one would find in a database, but the magic for Hadoop-like workloads is that it also has map and reduce transformations. Hence Tzoumas’ assertion that Flink is a successor to Hadoop—it provides all the same functionality but with much-needed benefits efficiency-wise at the map and reduce levels. For instance, when you want to do a join in MapReduce, you have to somehow fit the join into the MapReduce framework, which is no picnic. Since this system knows a join is needed, it can do it efficiently with the complexity of that process abstracted away via the transformation step.
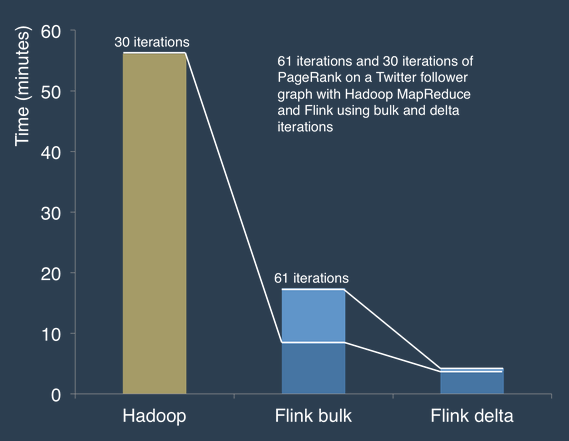
With this and the iterative and memory management magic that is woven in, algorithms like PageRank are prime benchmark candidates, especially since they utilize the “Delta” iterations which, to be light about it, take all the data that has already been processed and remove it from the iterative loop instead of resolving the same thing over and over—freeing up memory and compute.
Most of the benchmarks that Data Artisans is showing off are run on the Google Compute Engine public cloud without any fancy hardware choices beyond adding extra memory to virtual nodes. The benchmarks are based on hard disk as well, but one can only imagine what kind of across-the-board Hadoop-y boosts will happen when SSDs (or similar kin) become the norm and the disk is no longer such a painful bottleneck.
But what will be most interesting to watch is how a very small European company like Data Artisans plays its commercial open source cards. With early support from Hortonworks (which is strange since Hortonworks just introduced open source Tez, which targets similar problems) and others, Data Artisans might be absorbed as quickly as it emerged. If not, seeing how independent commercial support for Flink will play out will be equally interesting. Data Artisans co-founder Tzoumas is confident that the growing list of contributors will push its viability—but Flink’s best opportunity might lie inside the halls of a distro vendor, especially if they’re claiming they can eat Hadoop’s lunch.
“The good news is that we are living in an era of choice,” says Tzoumas. “The world is very different than a few years ago when infrastructure was mostly closed-sourced. There are choices at every level of the data management stack.”


China’s Hyperscalers Strive to Keep Pace in Open Source
We have a good sense of what projects U.S. companies open source but when it comes to Chinese webscale companies, most notably the big three—Baidu, Alibaba, and Tencent—that ecosystem is less public and not often discussed. For instance, even if you work in open source at a large company, it …

An Opaque Alternative to Oblivious Cloud Analytics
Data security has always been a key concern as organizations look to leverage the operational and cost efficiencies that come with cloud computing. Huge volumes of critical and sensitive data often are in transit and distributed among multiple systems, and increasingly are being collected and analyzed in cloud-based big data …

Can Open Source Hardware Crack Semiconductor Industry Economics?
The running joke is that when a headline begs a question, the answer is, quite simply, “No.” However, when the question is multi-layered, wrought with dependencies that stretch across an entire supply chain, user bases, and device range, and across companies in the throes of their own economic and production …
Be the first to comment