

A few years ago, DirectData Networks gave us a hint at the tectonic-like shifts that were emerging in datacenters at enterprises and high-end research institutions and were shaping the strategy of a company that had made its name in HPC with its parallel file system technology. New performance and storage demands were put on datacenters by containers, clouds, analytics workloads, and other forces, particularly the rapid evolution of AI.
DDN, like many others in the IT industry, saw that coming and adapted accordingly.
“What DDN has been focused on over the last four years is creating these highly efficient platforms for data storage, specifically for large AI systems,” Kurt Kuckein, vice president of marketing, tells The Next Platform. “Enterprise AI has been our big expansion area. We haven’t left HPC behind, but a lot of the work that we’ve been doing has been to take what was previously a fairly sophisticated and complicated parallel file system and make it much more consumable to a wider audience. This has really met up with this huge demand that we’re seeing, and we’re starting to see an even bigger demand just recently based on the generative AI stuff in the market.”
That AI push is continuing as DDN is at the ISC23 supercomputing show in Germany this week. In the run up to the event, DDN said it is adding QLC SSD storage and data compression to its ExaScaler portfolio as a high-performance and economical option for running AI and machine learning workloads.

Generative AI – popularized by such technologies as OpenAI’s GPT-4, ChatGPT, and Dall-E, which have been embraced and hyped by Microsoft in recent months – and the large-language models (LLMs) behind them demand high-performing compute and storage. As vendors like Nvidia, with offerings like its DGX supercomputers, DGX SuperPODs AI clusters, H100 “Hopper” GPUs, and Arm-based “Grace” CPUs, roll out more AI-focused compute architectures, there will be more call for storage capabilities to match them.
DDN started to focus on AI soon after Nvidia began rolling out systems like the DGX SuperPOD.
“That has been a really huge growth area for us,” Kuckein says. “We’re finding a lot of success, especially at the high end of these systems, so folks who are deploying these DGX SuperPODs, currently with DGX A100. We see the need increasing even more when the DGX H100 started shipping in higher volumes. It’s taking that system that was already really I/O-hungry and 4X-ing that, so it makes the parallel file system even more important. We’ve seen our growth primarily come in that space over the last four years.”
Parallel file systems, which stores data from datasets across myriad networked servers and runs coordinated IOPS between clients and storage nodes, are a good fit for the AI space for many of the reasons that make them work for HPC. Scalability is key.
“The ability for a client, the DGX system, to be able to see all of the backend data over all of the parallel paths takes away a lot of the bottlenecks that are run into at this scale with something like an NFS file system, which is a point-to-point protocol, has an overhead to it, and is going to top out at a certain level,” he says. “It won’t be able to scale once you’re getting into these 10-, 20-plus DGX system environments, where we can continue to scale linearly and provide those parallel pathways.”
It is a plus for both the performance of the individual client and the “aggregate performance across the entire cluster, where a single one of our systems can drive 90 GB/sec per second and then we scale those systems out. It makes it much simpler than other solutions that are primarily based on NFS today. It’s really simple to set up and people are familiar with that protocol but as soon as you get into these sizes of environments, it gets very, very complex to try to make those systems scale.”
DDN’s portfolio includes its A3I reference infrastructure that integrates its storage with other’s compute systems. With Nvidia, it integrated with the DGX A100 systems, but in March the company said it is now compatible with the DGX H100 supercomputers. At SC22 last November, DDN said it was working with Atos BullSequana XH3000 supercomputers to run AI workloads.
Now comes the new ExaScaler system, the A1400X2 QLC, that adds another option for enterprises running AI workloads. The array introduces a QLC option to a flash lineup that Kuckein says typically has been TLC-only and came in either a scale-out flavor with flash or scale-up with hybrid HDDs and a feature called Hot Pools – an automated tiering system for Lustre – managing the data between them.
The move now is to offer a QLC choice as a more cost-effective layer. Most competitive QLC offerings use NFS as the protocol and come with complicated backups involving an I/O server with storage-class memory or something similar and a QLC layer attached via switched network, all of which is costly and difficult to scale.

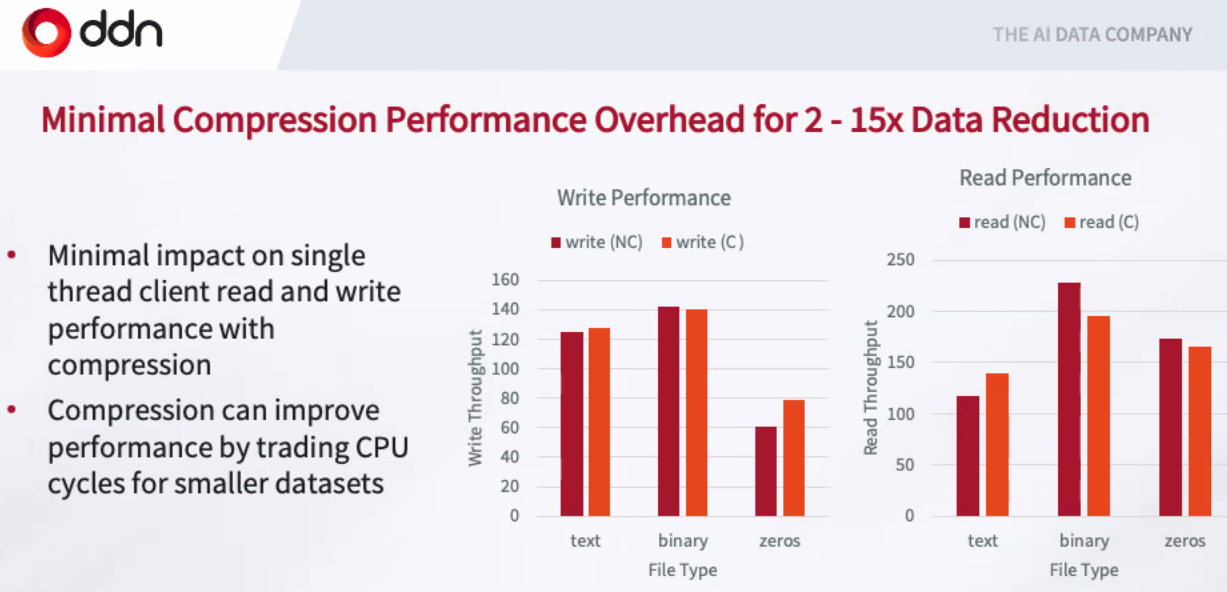
For the QLC backend, DDN is using NVM-Express-over-fabrics that hangs off the back of the appliances. At the same time, the company is introducing a client-side compression capacity that it says will deliver a 2X to 15X reduction in data, essentially delivering the expected performance at twice the density, Kuckein says. With QLC enclosures – DDN is using 60 TB QLC drives for 1.4 PB capacity in each 2U chassis for twice the capacity-per-watt than competitors – behind an all-flash TLC back, DDN c.an get up to 8 PB of combined TLC and QLC performance in 12 units.
The A1400X2 can deliver 10 times more data than other systems and use less power.
“With these really data-hungry applications, everybody’s pushing to get more and more data into fewer systems,” he says. “We’re using NVMe-over-fabrics – Ethernet backends – on these systems, so direct communication from the dual controller head back to these very resilient QLC enclosures. There’s no external switching required or anything like that. It’s all a self-contained unit that we can scale out.”
For organizations, it’s a matter of choice. For the best performance, they can choose TLC for up to. The QLC option for the best all-flash economics comes up to 61 TB and the lowest cost per terabyte comes with the hybrid TLC-HDD system and up to 22 TB.

As DDN continues its deep dive into the AI space, it won’t be alone in either targeting such workloads or working with Nvidia. The GPU maker last fall rolled out the BasePOD, a scalable reference architecture for AI datacenter workloads based on DGX A100 GPU server that also calls for storage and networking switches from partners.
It’s the basis for DDN’s A3I. At the same time, several other storage vendors, including NetApp, Dell, Weka, Pure Storage and Vast Data also signed on as Nvidia BasePOD partners and other BasePOD reference architectures based on their own technologies. It’s going to be a crowded space.




Be the first to comment