

It is relatively easy to get a group of people that creates a new database management system or new data store. We know this because over the past five decades of computing, the rate of proliferation of tools to provide structure to data has increased, and it looks like at an increasing rate at that. Thanks in no small part to the innovation by the hyperscalers and cloud builders as well as academics who just plain like mucking around in the guts of a database to prove a point.
But it is another thing entirely to take an open source database or data store project and turn it into a business that can provide enterprise-grade fit and finish and support a much wider variety of use cases and customer types and sizes. This is hard work, and it takes a lot of people, focus, money – and luck.
This is the task that Dipti Borkar, Steven Mih, and David Simmen took on when they launched Ahana two years ago to commercialize the PrestoDB variant of the Presto distributed SQL engine created by Facebook, and no coincidentally, it is a similar task that the original creators of Presto have taken on with the PrestoSQL, now called Trinio, variant of Presto that is commercialized by their company, called Starburst. In either case, these Presto variants federate databases and data stores and provide a universal SQL layer that allows them to be queries in place – a very powerful capability that is made necessary by the persistence of legacy databases and the gravity of data.
It is just too hard to move it all into one place to query it, which is what companies tried to do to create data warehouses. And even then, data warehouses usually only had summary data, and while they had the advantage of convenience once the data is in the warehouse, getting data in the warehouse (and making sure it is not garbage – was a tremendous pain in the neck. In short, as we put it a few months ago, you want to do data analytics without the data warehouse, which is the exact opposite of what database industry darling Snowflake does with its cloud data warehouse.
So much do that more and more companies want to query across data where it sits using something like PrestoDB. And that is why Ahana has been able to extend its Series A funding announced in August last year, where Google Ventures, Lux Capital, Third Point Ventures, and Leslie Capital kicked in $27.2 million to augment the $4.8 million in seed funding Ahana raised to get started in 2020. With the Series A extension, Liberty Global Ventures, the venture capital arm of the telecom company by the same company that has operations throughout Europe, along with some more participation by Google Ventures, is kicking in another $7.2 million to the Series A kitty. (We strongly suspect that Liberty Global is a customer of Ahana, but chief executive officer Steven Mih won’t comment on that.) That brings the total haul so far to $32 million, and Mih adds that Ahana was not looking to raise money. To which we quipped in this current economic climate, if someone offers you money, you find a reason to take it.
In the ten months since the first tranche of the Series A funding came in, Ahana has more than doubled its staff to just under 50 people, and over 100,000 copies of its Ahana implementation of PrestoDB have been downloaded. Mih is not at liberty to say how many paid customers it has on the commercial-grade Ahana Cloud implementation of the database.
As far as growing the company’s payroll, Mih is being understandably cautious. “We want to get a handle on what’s happening with the global economy and possible headwinds associated with that,” Mih tells The Next Platform, refraining to use the R word. “And if some potential issues don’t happen, then we will be growing really fast.”
That growth is being driven by the need to do federated queries across database platforms, which has only been made more obvious by the notions of multimodal data processing, which has been eloquently described by Matt Bornstein, Jennifer Li, and Martin Casado (one of the creators of OpenFlow and one of the co-founders of Nicira, which gave VMware its NSX virtual networking stack), all who prowl the world for good tech investments for Andreesen Horowitz.
At the heart of this modern data processing architecture is what is called a data lakehouse – part data warehouse from days gone by and part data lake from the Hadoop era, but really just cheap and deep storage without the need to use MapReduce to chew through the unstructured data on a cluster of machines.
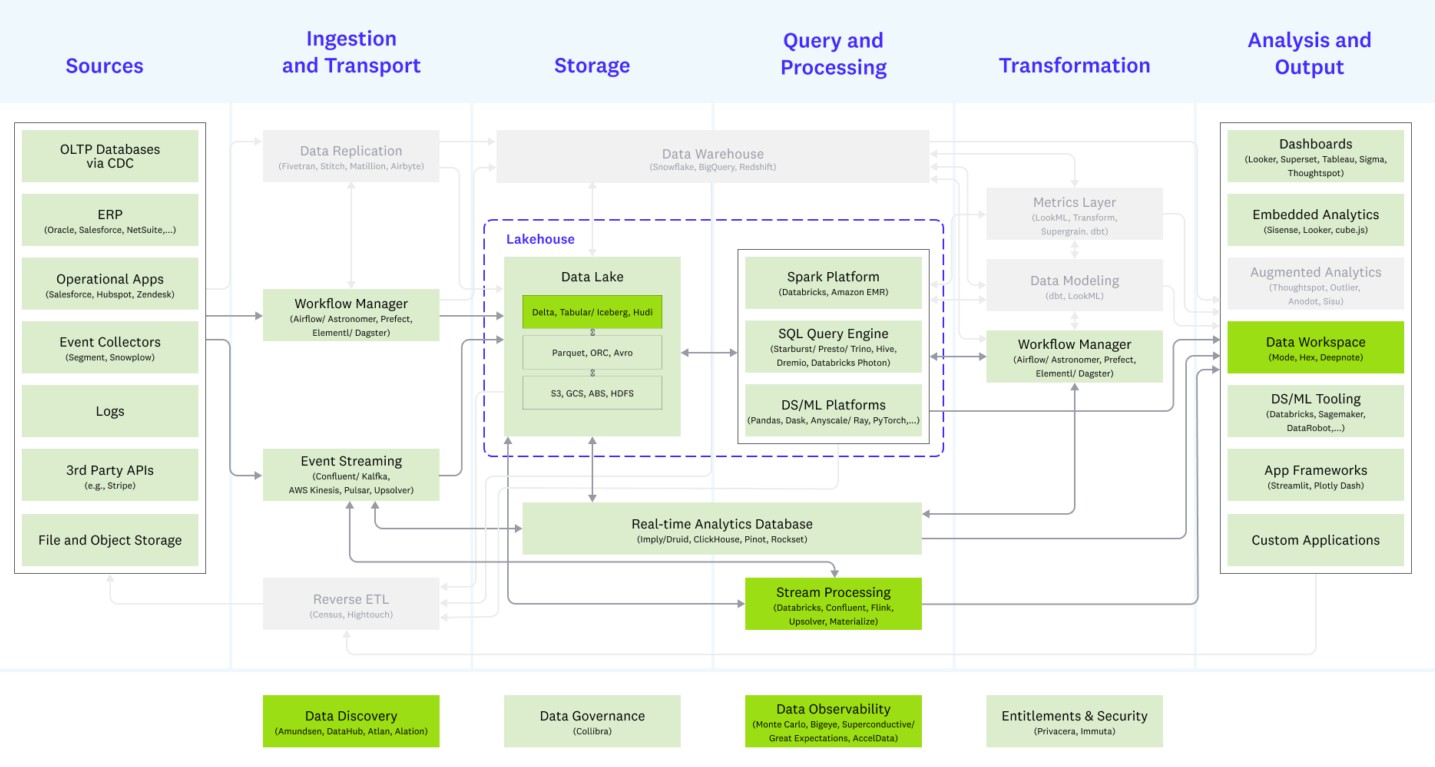
This chart from Mih sums it up the center of that chart little more cleanly and legibly:

“As you know, there is a lot of data that’s being pumped into data lakes – and that’s semi-structured, structured, and unstructured data,” Mih explains. “With everything being commodified, people as asking why they should put data into another proprietary store like a data warehouse and why they should leave it in open formats. And if they did try to put such data into commodified storage, the compute on the data warehouse is proprietary. The idea of the data lakehouse is to use open source compute, and Presto for SQL query processing is one of the main options. And then for the non-SQL queries and workloads, you can use ML and AI frameworks for compute and formats like Parquet for that. The storage is a commodity with the lakehouse, and the compute layer is really where the costs still are, and Presto is well positioned to play here as a query engine alongside frameworks that access unstructured data.”
That overall multimodal data processing architecture has a lot of moving pieces, and if Ahana is to be successful commercializing PrestoDB and federating the distributed query engine across all kinds of relational data stores, the it is going to have to get easier to install and test the SQL heart of a data lakehouse. That is what the new Community Edition of Ahana Cloud for Presto is all about. It is a free and unlimited version of the database that can run on any single cluster, regardless of size. (Most Presto customers have multiple clusters, and that is where the subscriptions will kick in.) Here are the differences between the Community Edition and the full-on Ahana Cloud for Presto edition:

The Community Edition runs on the Amazon Web Services cloud, just like the production Ahana Cloud for Presto does, and as long as it is running on only a single cluster – no matter how many EC2 instances are driving it – Community Edition is free. There are some caveats. The Community Edition does not support Graviton, Graviton2, or Graviton3 instances, and it has only community support. If you want the Ahana Cloud for Presto enterprise-grade edition, you can seamlessly upgrade to it and then you can has as many clusters as you want and run on any AWS instance type, including the Graviton Arm server CPU family that AWS has created for its own use. The production version also has higher security, performance enhancements such as autoscaling on AWS, and of course, tech support from live human beings employed by Ahana. You can upgrade from Community Edition to Ahana Cloud for Presto (which should just have its name changed to Enterprise Edition. Ahana Cloud for Presto costs anywhere from a couple of hundred dollars to thousands of dollars per month to license on a modest setup on AWS, and this does not include the cost of EC2 instances and storage.
Now, Ahana has something to get people started fast with Presto and save them the days or weeks it would take to set up Presto atop a data lakehouse. Just grab this container, turn it on, and point it at the data lakehouse, and start whacking it with SQL queries. And each one of these Community Edition users can use it forever and never pay for it until they have a second cluster or need enhanced security or performance.

Meta’s Velox Means Database Performance Is Not Subject To Interpretation
A decade and a half ago, when Dennard scaling ran out of gas and many of us were starting to first think about what the end of Moore’s Law might look like should that day ever come, a bunch of us were kicking around what it might mean. People brought …

Presto Is The Third Time Charm For Federated Databases
Users of relational database management systems are accustomed to sub-second response for relatively simple online transaction processing, and have been able to enjoy those zippy responses for decades. The big caveat there is relatively simple transactions – looking up data or processing an order – and against fairly modest databases …

The Once And Future Federated Database
There are many different schools of thought when it comes to databases, which is one of the reasons that we launch our inaugural event focused solely on database technologies this year. But if you had to sum it up, it would look a bit like the following. After deploying a …
very interesting and I like the information conveyed