
Always on the lookout for the kernel of a new platform, we chronicled the steady rise and sharp fall of Hadoop as the go-to open source analytics platform. In fact, we watched it morph into a relational database of sorts only to end up being cheap storage for unstructured data. To morph into what is essentially a legacy platform already.
Even Cloudera – essentially the lone survivor among the top Hadoop vendors that includes Hortonworks (which Cloudera bought for $5.2 billion in 2019) and MapR, bought by Hewlett Packard Enterprise the same year – shifted away from Hadoop when it launched its Cloudera Data Platform in 2019 and now says Hadoop is one of more than two dozen open source projects that form the foundation of the platform.
That said, many enterprises made significant investments in money, time, and engineering into their Hadoop environments over the years and have petabytes of data still running in them. Migrating those massive datasets out of on-premises Hadoop and into the cloud is not an easy task and comes with its own share of stresses, such as data security and sovereignty, particularly as more enterprises adopt multicloud approaches. There is no shortage of vendors offering tools to help move all that into the public cloud, with the names ranging from WAN Disco and IBM to Infosys and Snowflake, not to mention the cloud providers themselves.
Infoworks is one of the many peddling tools – in this case, one called Replicator and just in its 4.0 release – to move on-premises Hadoop data lakes to the cloud faster and using fewer resources than competing tools.
“The Infoworks Replicator specifically accelerates Hadoop data and metadata migrations, but the Infoworks platform also supports enterprise data warehouse migrations as well,” company co-founder and CTO Amar Arsikere tells The Next Platform. “With Infoworks, what we have seen – and we have proven it in POCs – is that our customers are able to migrate to three to five X faster at one-third the cost of other approaches that typically use hand coding with some point products with a lot of glue code. The reason we are able to do that is because of the high degree of automation.”
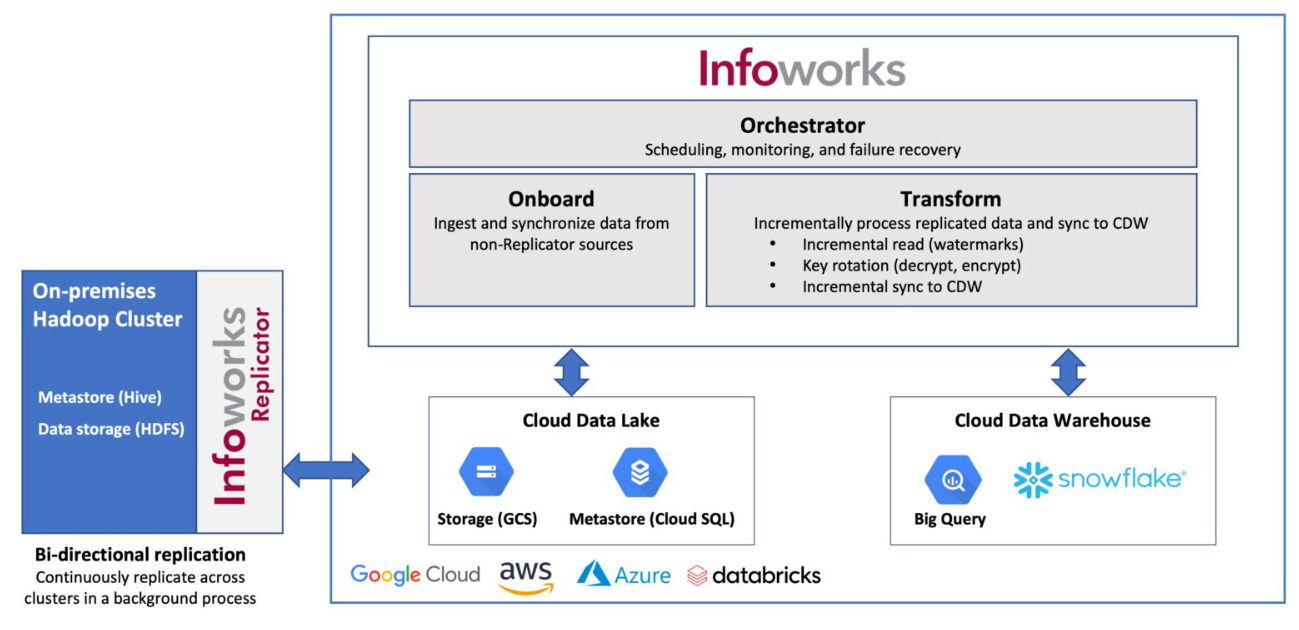
Replicator has “data crawlers that will crawl and understand and really set up all of these migrations, both for data, metadata as well as workloads. That gives you a scalable architecture to move petabytes-sized datasets and workloads running tens of thousands, if not hundreds of thousand [of petabytes]. Automation is absolutely must, especially for large enterprises.”
Arsikere has had his hands in big data for years. He spent more than three years at Google as part of its cloud effort, leading the effort to build a petabyte-scale analytics platform on the BigTable NoSQL database service that included thousands of users, and then went to Zynga, which runs social video game services. While there, he and his team helped create the Membase database that later merged with CouchOne to become Couchbase.
Eight years ago, Arsikere helped found Infoworks, and today its customers are Fortune 500 companies in such industries as healthcare, telecommunications, insurance, and retail and many of them have sensitive data that needs to comply with myriad regulations like HIPAA. So Replicator needs to be able to integrate with encryption and other security technologies while the data is being moved.
At Infoworks, Arsikere and others focused on helping move and run their data at scale in the cloud and saw the challenges Hadoop users faced. Some want to move to a cloud flavor of Hadoop, though most are seeking a cloud-based architecture or cloud data warehouse, such as Snowflake or Google Cloud’s BigQuery warehouse. Infoworks’ technology enables enterprises to run in Spark-based or cloud data warehouse architectures.
“We are seeing more folks who are more ready to do this,” he says. “The start of this comes with the static infrastructure issue. There is a cost consideration as well. Some of the decisions have been made in the sense that there is a date when they might be decommissioning [hardware]. What we see is there is an urgency and there is also a realization that they need hundreds of people to do this work and they don’t have enough time. With Replicator, you could be doing petabytes of data movement with literally two people. We have we have done that in production because of the amount of the automation.”
Replicator is run as a service, ensuring continuous operation and synchronization between on-premises Hadoop clusters and those in the cloud and to provide scalability in petabytes of data. The automation and scalability are important when talking about massive Hadoop workloads.
“You can set up your source cluster and your target cluster and it automatically computes the difference between the two clusters at petabyte back in a very fast manner,” he says. “It continuously brings the two clusters together so you can incrementally replicate the clusters that come up. You can update both the clusters and it also provides an ability to run the Replicator by some bandwidth throttling, which means you can throttle the bandwidth at different thresholds – one for daytime night, daylight and weekends – because these are petabyte-size clusters. It will take months.”
It took one Infoworks customer, a credit card company, nine months before they were off their on-premises cluster, Arsikere says.
“Replicator is set up as a as a background process, in that it’s running all the time,” he says. “Typically you don’t migrate the whole thing in one shot. You may have to move use case-by-use case, you may do business domain-by-business domain. They chose to just do it in stages. That’s how they ended with nine months.”
Beyond selecting the tables and the scheduling, all the processes are automated. That includes coding and fault tolerance. The service is bi-directional, which means that during part of it means master data moving between on-premises and the cloud. Organizations can change the direction of the table via configurations changes rather than coding.
While Infoworks’ goal is to help enterprises move the massive amounts of data in their Hadoop environments to the cloud, Arsikere says the message the vendor brings to organizations is to use the opportunity to modernize their IT operations.
“For any enterprise, especially when they are looking to really be platformed in the cloud, this is a moment of crisis, which you should not waste,” he says. “When you are migrating to the cloud, you should do it in a way where you’re getting the benefit of the cloud, that you are able to take advantage of different compute options in the cloud, like Spark vs. cloud data warehouses. This is the time to modernize it. When we talk about it at Infoworks, those workloads can run in any compute option. If you just do a lift-and-shift, you’re not getting the benefits, so what is the point of moving to the cloud? If you are on premises with static compute infrastructure and you move to the cloud with the same static compute infrastructure, there’s no benefit for the business. Why do it? Modernization when you migrate to the cloud is very important to get that agility.”


The Endless Pursuit Of Scale At LinkedIn
There is nothing at all wrong with legacy application and system software as long as it can deliver scalability, reliability, and performance. Changing from one software stack to another is so difficult and so risky — the proverbial changing of the front two tires on the car while going down …
The Opposite Of Snowflake: Analytics Without The Data Warehouse
As we have pointed out before, large enterprises have to deal with a different kind of scale issue than the hyperscalers, and in many ways, the hyperscalers have it easier. The hyperscalers have dozens of core applications that they have to run at massive data scale – pushing up to …

Why the Fortune 500 is (Just) Finally Dumping Hadoop
Remember how, just a decade ago, Hadoop was the cure to all the world’s large-scale enterprise IT problems? And how companies like Cloudera dominated the scene, swallowing competitors including Hortonworks? Oh, and the endless use cases about incredible performance and cost savings and the whole ecosystem of spin-off Apache tools …
Be the first to comment