

Commissioned In just about any situation where you are making capital investments in equipment, you are worried about three things: performance, price/performance, and total cost of ownership. Without some sort of benchmark on which to gauge performance and without some sense of relative pricing, it is impossible to calculate total cost of ownership, and therefore, it is impossible to try to figure out what to invest the budget in.
This is as true for the advanced systems that run AI applications as it is for a cargo aircraft, a bulldozer, or an electric locomotive. And this is why the MLPerf benchmark suite is so important. MLPerf was created only three and a half years ago by researchers and engineers from Baidu, Google, Harvard University, Stanford University, and the University of California Berkeley and it is now administered by the MLCommons consortium, formed in December 2020. Very quickly, it has become a key suite of tests that hardware and software vendors use to demonstrate the performance of their AI systems and that end user customers depend on to help them make architectural choices for their AI systems.
MLCommons now has over 70 member organizations, which include researchers at top universities, hyperscalers and cloud builders, and semiconductor makers trying to prove they have the best compute engines for AI. The MLPerf benchmark suite started out with machine learning training tests in February 2018, followed quickly by a separate set of training benchmarks aimed at running training workloads on classical supercomputers aimed at HPC simulation and modeling. Supercomputers increasingly use AI algorithms to enhance the performance of traditional HPC applications, so the architectures of these machines are sometimes – but not always – different from systems that are set up purely to run machine learning training or inference. In the summer of 2019, MLPerf released a set of machine learning inference benchmarks, and has expanded out into mobile devices as well.
As we previously discussed, Inspur’s server business is exploding and it has become the number three server maker in the world, behind Dell and Hewlett Packard Enterprise and blowing past Lenovo, Cisco Systems, and IBM as if they were sitting still. And part of the reason why is that Inspur’s sales of systems to run AI applications is skyrocketing, making it one of the fastest growing products in the company’s three decades in the server business and now driving about 20 percent of its X86 server shipments and in the next five years is forecast to be more than 30 percent of shipments.
Given the importance of AI workloads to the Inspur server business, it comes as no surprise that Inspur has been an early and enthusiastic supporter of the MLPerf benchmarks and was a founding member of MLCommons. The MLPerf benchmark suite will create a virtuous cycle, driving hardware and software engineers to co-design their systems for the many different types of AI algorithms that are used for image recognition, recommendation engines, and such. IT equipment makers that sell AI systems (and usually traditional HPC systems, too) will learn from the experience of customers and get their requirements for future systems; this will drive the architecture of AI systems and the systems builders will no doubt advance in the rankings of the MLPerf tests, which will drive revenues and start the cycle again.
The key is to have a representative suite of benchmarks. Successful examples here included SPEC integer and floating point tests for raw CPU performance, which has become a gatekeeper of sorts for who gets to be in the CPU market; and the TPC suite that stress tested the transaction processing and data warehousing benchmarks of whole systems. There are others, like the High Performance Linpack and STREAM memory bandwidth and High Performance Conjugate Gradients benchmarks in the traditional HPC space. No one makes buying decisions based solely on any of these tests, of course, but the results help organizations pare the options and then know who to bring into their formal bidding process to fight for their business.
“We think that MLPerf today is based on the most popular AI workloads and scenarios, such as computer vision, natural language processing, and recommendation systems,” Gavin Wang, senior AI product manager at Inspur, tells The Next Platform. “When you look at the eight tasks in the MLPerf training benchmark, they represent the catalog of neural network models, and these scenarios are very representative for customers.”
The MLPerf v0.7 training benchmark results, which were announced in July 2020, are representative of who are the players and who are the winners when it comes to machine learning training. At that time, Alibaba, Dell, Fujitsu, Google, Inspur, Intel, Nvidia, SIAT, and Tencent submitted benchmark results for their systems, and here is the ranking of the top nine single-node machines running the ResNet50 image recognition benchmark suite against the ImageNet dataset, which has 1.28 million images:
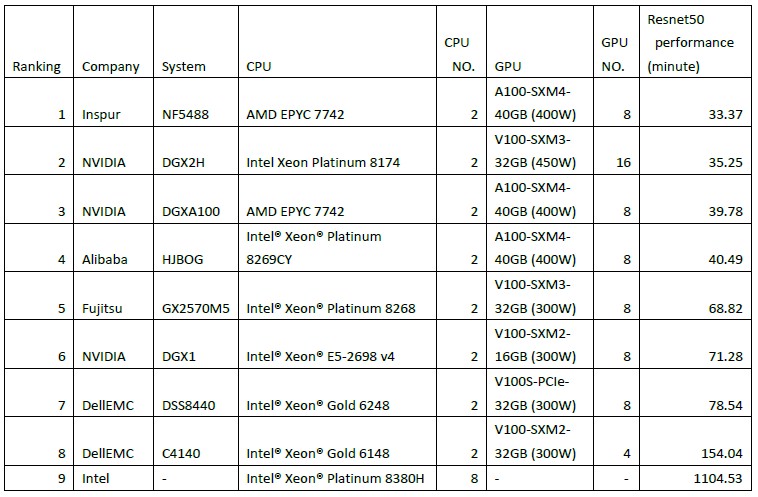
The ResNet50 performance is expressed in the number of minutes it takes to train the model against the ImageNet library, and as you can see, Inspur’s NF5488A5 system, which had a pair of AMD Epyc 7724 processors and eight Nvidia A100 SMX4 GPU accelerators with 40 GB each was able to do the ResNet part of the MLPerf training suite in 33.37 minutes. That was 16.1 percent faster than Nvidia’s DGX A100 system with the CPU and GPU components, which just goes to show you that Inspur’s techies know a thing or two about tuning AI software and hardware. (Beating Nvidia at its own game is no easy feat.)
The Nvidia A100 GPU accelerators were fairly new at the time the MLPerf v0.7 training benchmarks were run, and a lot of the machines tested were using the earlier Nvidia V100 GPU accelerators – and in some cases a lot more of them. These results show how architectural changes between compute generations drive up performance and drive down training times. Over the years, MLCommons will be able to plot the performance jumps within generations of similar CPU, GPU, FPGA, and custom ASIC devices as well as architectural leaps across these different kinds of devices for both training and inference workloads.
But as Wang says, one must not discount the importance of tuning the hardware and the software together, which Inspur does for customers for real workloads as well as for its own MLPerf benchmark runs. The expertise carries over. “We run MLPerf tests, and we have unique design and software tuning capabilities, and customers can look at all of this and see how it relates to their AI applications and workflows.”
Don’t get the wrong impression and think that Inspur is limiting its AI training and inference platforms to just GPUs with host processing from CPUs. “Performance is one thing that we can bring to the customer, but we can also bring a large ecosystem,” says Wang, referring to the ability to support other CPUs and accelerators inside of AI systems. “We have done MLPerf optimizations and have open sourced the code to GitHub so we can help customers achieve faster AI performance on their applications, and we are proving to them, with the help of MLPerf, that we can deliver a total AI solution, not just hardware.”
The other thing that Inspur can do is leverage its vast supply chain and the scale of its server business to help drive the cost of AI systems down and the price/performance up. The MLPerf benchmarks do not, as yet, include pricing for the systems under test, but perhaps someday they will take a lesson from the TPC transaction processing benchmarks from days gone by and start adding cost data to the test so bang for the buck can be calculated. It would be a good thing to know the power that AI systems consumed doing their work, too, since power consumption is a gating factor in AI system architecture and electricity is not free.
Commissioned by Inspur


Talking Servers With Inspur And Intel
Any time a server maker comes into the global market and bypasses Cisco Systems, Lenovo, and IBM to become the third largest seller of machines in the world, you should pay attention. This is precisely what Inspur Information, the server unit of Chinese IT supplier Inspur Group, has accomplished, and …
Getting Ahead Of The Game: Inspur’s Machine For Digital Twins And Immersive Experiences
Commissioned: Not everybody wants to be Iron Man. But there isn’t an artist or engineer around that doesn’t envy the 3D, immersive design experience that Tony Stark used to invent new equipment and analyze his existing gadgets in the Avenger movies. We have been imagining an immersive experience combining the …

Server Budgets On The Mend As Pandemic Tries To End
Businesses are judged quarter on quarter and year on year, but you have to look at the long haul and the flow of all business over time to really judge properly. That’s why we are data wonks here at The Next Platform. And it is also why we are relieved …