

Since 1965, the computer industry has relied on Moore’s Law to accelerate innovation, pushing more transistors into integrated circuits to improve computation performance. Making transistors smaller helped “lift all boats” for the entire industry and enable new applications. At some point, we will reach a physical limit – that is, a limit stemming from physics itself. Even with this setback, improvements kept on pace thanks to increased parallelism of computation and consolidation of specialized functions into single chip packages, such as systems on chip).
In recent years, we are nearing another peak. This article proposes to improve computation performance not only by building better hardware, but by changing how we use existing hardware. More specifically, the focusing on how we use existing processor types. I call this approach Compute Orchestration: automatic optimization of machine code to best use the modern datacenter hardware (again, with special emphasis on different processor types).
So what is compute orchestration? It is the embracing of hardware diversity to support software.
There are many types of processors: Microprocessors in small devices, general purpose CPUs in computers and servers, GPUs for graphics and compute, and programmable hardware like FPGAs. In recent years, specialized processors like TPUs and neuromorphic processors for machine learning are rapidly entering the datacenter.
There is potential in this variety: Instead of statically utilizing each processor for pre-defined functions, we can use existing processors as a swarm, each processor working on the most suitable workloads. Doing that, we can potentially deliver more computation bandwidth with less power, lower latency and lower total cost of ownership).
Non-standard utilization of existing processors is already happening: GPUs, for example, were already adapted from processors dedicated to graphics into a core enterprise component. Today, GPUs are used for machine learning and cryptocurrency mining, for example.
I call the technology to utilize the processors as a swarm Compute Orchestration. Its tenets can be described in four simple bullets:
- Modern datacenters have various types of processors.
- To better use these processor types, we need smart allocation of workloads to specialized processors.
- Automation is a must. Developers can’t be the sole responsible for optimizing the code for the hardware, especially not for optimizing third party code they use.
- Better compilers are not the solution: optimization of machine code during runtime, smart allocation to specialized, and automatic hardware configuration are required.
Compute orchestration is, in short, automatic adaptation of binary code and automatic allocation to the most suitable processor types available. I split the evolution of compute orchestration into four generations:
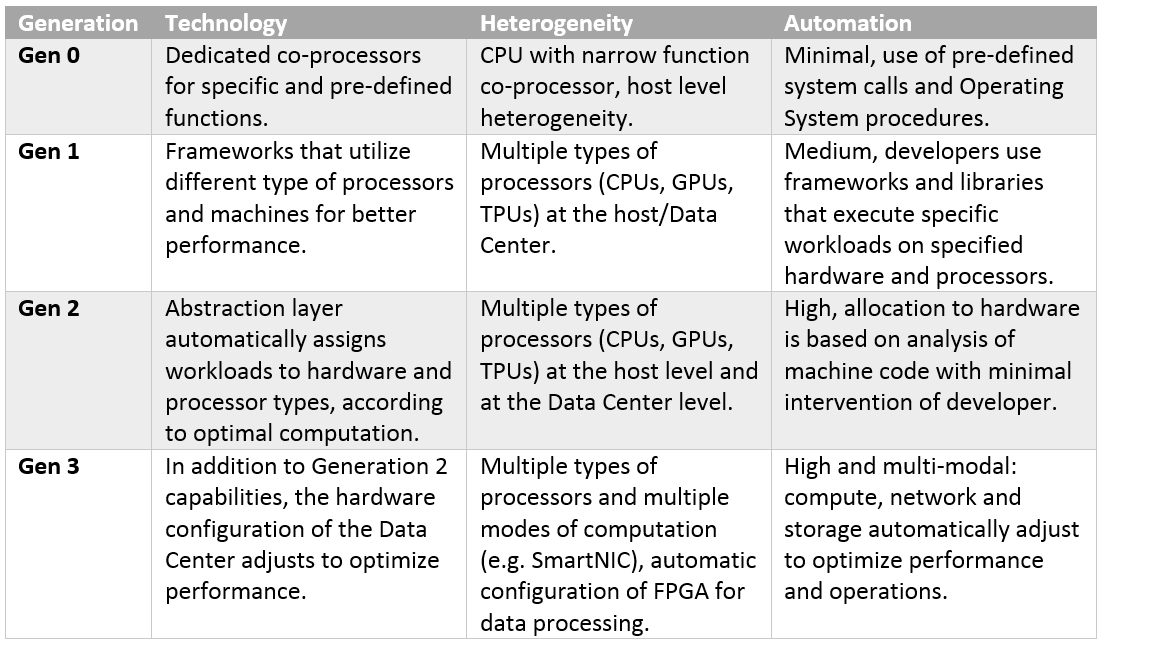
Compute Orchestration Gen 1: Static Allocation To Specialized Co-Processors

This type of compute orchestration is everywhere. Most devices today include co-processors to offload some specialized work from the CPU. Usually, the toolchain or runtime environment takes care of assigning workloads to the co-processor. This is seamless to the developer, but also limited in functionality.
Best known example is the use of cryptographic co-processors for relevant functions. Being liberal in our definitions of co-processor, Memory Management Units (MMUs) to manage virtual memory address translation can also be considered an example.
Compute Orchestration Gen 2: Static Allocation, Heterogeneous Hardware
This is where we are at now. In the second generation, the software relies on libraries, dedicated run time environments and VMs to best use the available hardware. Let’s call the collection of components that help better use the hardware “frameworks.” Current frameworks implement specific code to better use specific processors. Most prevalent are frameworks that know how to utilize GPUs in the cloud. Usually, better allocation to bare metal hosts remains the responsibility of the developer. For example, the developer/DevOps engineer needs to make sure a machine with GPU is available for the relevant microservice. This phenomenon is what brought me to think of Compute Orchestration in the first place, as it proves there is more “slack” in our current hardware.

Common frameworks like OpenCL allow programming compute kernels to run on different processors. TensorFlow allows assigning nodes in a computation graph to different processors (“devices”).
This better use of hardware by using existing frameworks is great. However, I believe there is a bigger edge. Existing frameworks still require effort from the developer to be optimal – they rely on the developer. Also, no legacy code from 2016 (for example) is ever going to utilize a modern datacenter GPU cluster. My view is that by developing automated and dynamic frameworks, that adapt to the hardware and workload, we can achieve another leap.
Compute Orchestration Gen 3: Dynamic Allocation To Heterogeneous Hardware

Computation can take an example from the storage industry: Products for better utilization and reliability of storage hardware have innovated for years. Storage startups develop abstraction layers and special filesystems that improve efficiency and reliability of existing storage hardware. Computation, on the other hand, remains a “stupid” allocation of hardware resources. Smart allocation of computation workloads to hardware could result in better performance and efficiency for big data centers (for example hyperscalers like cloud providers). The infrastructure for such allocation is here, with current data center designs pushing to more resource disaggregation, introduction of diverse accelerators, and increased work on automatic acceleration (for example: Workload-aware Automatic Parallelization for Multi-GPU DNN Training).
For high level resource management, we already have automatic allocation. For example, project Mesos (paper) focusing on fine-grained resource sharing, Slurm for cluster management, and several extensions using Kubernetes operators.
To further advance from here would require two steps: automatic mapping of available processors (which we call the compute environment) and workload adaptation. Imagine a situation where the developer doesn’t have to optimize her code to the hardware. Rather, the runtime environment identifies the available processing hardware and automatically optimizes the code. Cloud environments are heterogeneous and changing, and the code should change accordingly (in fact it’s not the code, but the execution model in the run time environment of the machine code).
Compute Orchestration Gen 4: Automatic Allocation To Dynamic Hardware

“A thought, even a possibility, can shatter and transform us.” – Friedrich Wilhelm Nietzsche
The quote above is to say that there we are far from practical implementation of the concept described here (as far as I know…). We can, however, imagine a technology that dynamically re-designs a data center to serve needs of running applications. This change in the way whole data centers meet computation needs as already started. FGPAs are used more often and appear in new places (FPGAs in hosts, FPGA machines in AWS, SmartNICs), providing the framework for constant reconfiguration of hardware.
To illustrate the idea, I will use an example: Microsoft initiated project Catapult, augmenting CPUs with an interconnected and configurable compute layer composed of programmable silicon. The timeline in the project’s website is fascinating. The project started off in 2010, aiming to improve search queries by using FPGAs. Quickly, it proposed the use of FPGAs as bumps in the wire, adding computation in new areas of the data path. Project Catapult also designed an architecture for using FPGAs as a distributed resource pool serving all the data center. Then, the project spun off Project BrainWave, utilizing FPGAs for accelerating AI/ML workloads.
This was just an example of innovation in how we compute. Quick online search will bring up several academic works on the topic. All we need to reach the 4th generation is some “idea synthesis,” combining a few concepts together:
Low effort HDL generation (for example Merlin compiler, BORPH)
- Support for execution on different processors (OpenCL and TensorFlow)
- Flexible data center infrastructure (i.e. interconnect and computation)
- Automatic deployment of code and smart scheduling (conceptual example, another one)
In essence, what I am proposing is to optimize computation by adding an abstraction layer that:
- Identifies the computation needs of running applications
- Predicts the best hardware configuration for the data center, given the current needs
- Adapts the hardware by re-configuring interconnects, network and FPGAs
- Optimizes the execution model/machine code to the new hardware configuration
- And allocates the code
Automatic allocation on agile hardware is the recipe for best utilizing existing resources: faster, greener, cheaper.
The trends and ideas mentioned in this article can lead to many places. It is very likely, that we are already working with existing hardware in the optimal way. It is my belief that we are in the midst of the improvement curve. In recent years, we had increased innovation in basic hardware building blocks, new processors for example, but we still have room to improve in overall allocation and utilization. The more we deploy new processors in the field, the more slack we have in our hardware stack. New concepts, like edge computing and resource disaggregation, bring new opportunities for optimizing legacy code by smarter execution. To achieve that, legacy code can’t be expected to be refactored. Developers and DevOps engineers can’t be expected to optimize for the cloud configuration. We just need to execute code in a smarter way – and that is the essence of compute orchestration.
The conceptual framework described in this article should be further explored. We first need to find the “killer app” (what type of software we optimize to which type of hardware). From there, we can generalize. I was recently asked in a round table “what is the next generation of computation? Quantum computing? Tensor Processor Units?” I responded that all of the above, but what we really need is better usage of the existing generation.
Guy Harpak is the head of technology at Mercedes-Benz Research & Devcelopment in its Tel Aviv, Israel facility. Please feel free to contact him on any thoughts on the topics above at harpakguy@gmail.com. Harpak notes that this contributed article reflects his personal opinion and is in no way related to people or companies that he works with or for.
Related Reading: If you find this article interesting, I would recommend researching the following topics:
- SmartNIC, composable/disaggregated infrastructure, Microsoft project catapult.
- Latest trends in processor development (for example Habana Labs, Hailo, BrainChip), Exascale Computing (EPI).
- Kubernetes, especially as it moves to the bare metal and virtual machines space (for example, KubeVirt)
Some interesting articles on similar topics:
Return Of The Runtimes: Rethinking The Language Runtime System For The Cloud 3.0 Era
The Deep Learning Revolution And Its Implications For Computer Architecture And Chip Design (by Jeffrey Dean from Google Research)
Beyond SmartNICs: Towards A Fully Programmable Cloud
Hyperscale Cloud: Reimagining Datacenters From Hardware To Applications


AMD Rides The High Performance Computing Megacycle
Server buyers have longer memories and perhaps deeper disappointment of AMD’s exit from the X86 server processor business than consumers who buy PCs, and a manufacturing constrained Intel has clearly sacrificed some Core PC chip market share to maintain some Xeon SP server market share over the past two years. …
Hyperscalers And Clouds Lift Arista Networks Sky High
A massive buildout of infrastructure is happening within the datacenter walls of at least several of the hyperscalers and large clouds in the world if the financial results of Arista Networks, the upstart switch maker that has been taking on Cisco Systems in the datacenter with machines based on merchant …

Intel’s Datacenter Decline Not As Bad As Expected
Incoming chief executive officer and long-time Intel employee Pat Gelsinger is talking the helm of a chip company that has plenty of issues to sort out, but there is some good news as Intel reports its financial results for the fourth quarter of 2020 and Gelsinger gets ready to take …
Be the first to comment