

Enterprises are putting a lot of time, money, and resources behind their nascent artificial intelligence efforts, banking on the fact that they can automate the way application leverage the massive amounts of customer and operational data they are keeping. The challenge is not just to bringing machine learning into the datacenter. It has to fit into the workflow without impeding it. For many, that’s easier said and done.
Dotscience, a startup comprised of veterans from the DevOps world, dropped out of stealth mode this week and published a report that showed that enterprises may not be reaping the rewards from the dollars they are putting behind their AI projects. According to the report, based on a survey of 500 IT professionals, more than 63 percent of businesses are spending anywhere from $500,000 to $10 million on AI programs, while more than 60 percent also said they are confronting challenges with the operations of these programs. Another 64.4 percent that are deploying AI in their environments found that it is taking between seven and 18 months to move these AI workloads from an idea into production.
Not surprisingly, at the same time that it is coming out of stealth and releasing the report, Dotscience also is coming out with a product aimed at enabling companies to better put their machine learning plans into operation, a platform that wants to offer the tools that will do for machine learning what DevOps did for software development.
“There’s a huge amount of excitement around AI development,” Mark Coleman, vice president of product and marketing at Dotscience, tells The Next Platform. “Some teams are already reaping the benefits of investing in this area, but it’s quite a long tail in terms of assurances. If you think about a big, well-funded engineering and cloud companies like Google or Uber or Netflix, we see that they’ve already made significant investments so that operationalizing machine learning is sort of on par with what you would expect from modern software teams. But it’s this huge long tail of others that are doing it in ways that are suboptimal. The results vary massively, which is why we’re referring to it as the Wild West.”
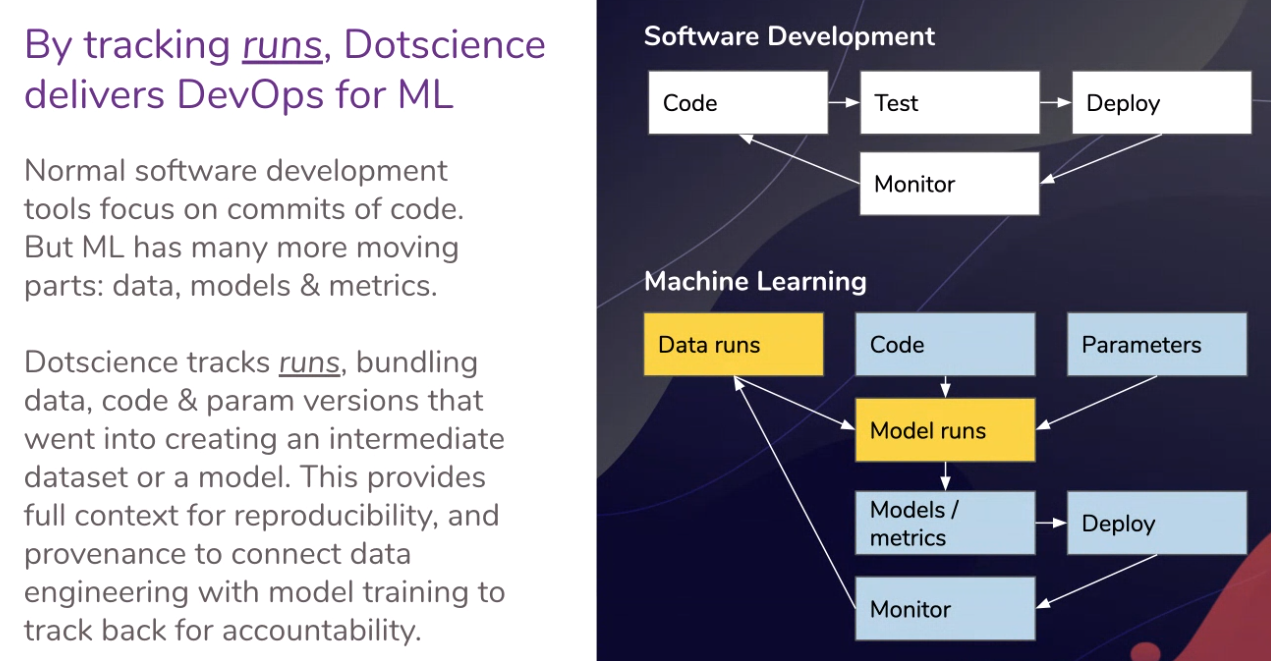
Coleman sees machine learning and data science at the same point in its curve as more generic software development was at before DevOps hit the scene several years ago. There were silos of development, testing and operations, and communications and collaboration between these groups were rare, causing conflicts and wasted time and money. DevOps brought with it version control and other capabilities that enabled workflows, collaboration and application code that could be easily reproduced. Dotscience, with its platform, wants to bring similar capabilities like version control to machine learning that are specific to the needs of the engineers in the field, who are working not only with code but also models and data.
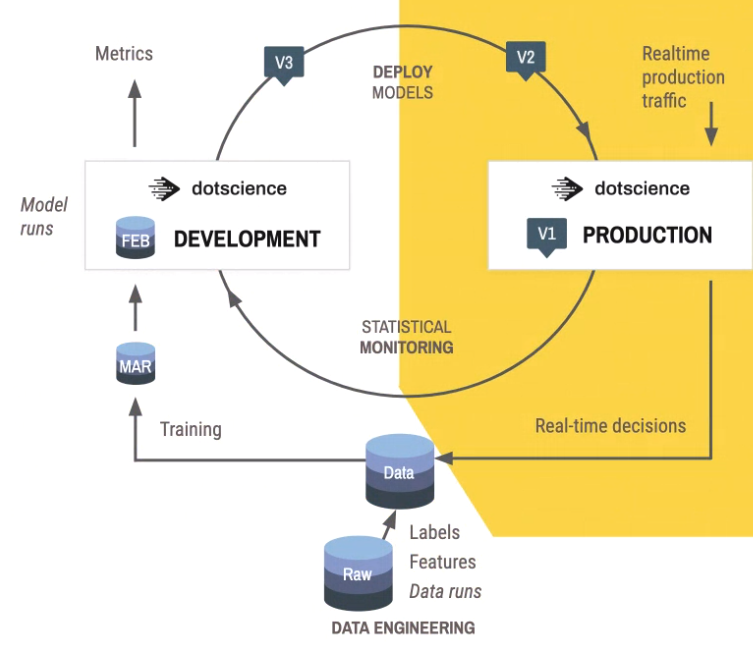
There’s a need to ensure that not only can machine learning developers collaborate and make code that can be reproduced but also easily track models and data, trace the a model from its training data back to the raw data (provenance), view relationships between parameters and metrics and monitor models to ensure they are behaving as expected. In addition, they need to be able to attach external S3 datasets and to attach to any system, from a laptop and a GPU-powered machine to datacenter hardware and cloud instances.
“With machine learning, we’ve got a few more variables going on, so we want to know about the code that creates the model, we need to know about all the parameters to the code that creates the model,” Coleman says. “We need to know about the test data and the training data. We also want to know about the metrics. Very often in normal software development you might just get all the tests going green locally, then push its continuous integration, triggered, it goes green there and then you just keep going through. In machine learning, you typically want to collaborate around things a little bit more. As you’re developing, you’re not necessarily committing everything, but you do want to see what metrics you and your colleagues are getting. What we’re seeing is a lot of teams basically just go in with a random approach to choosing algorithms or some of this stuff. If they’re given a problem, they’ll say, ‘You try this and I’ll try that and let’s see what happens.’ Over time you can see that the good solutions are converging and that’s why reproducibility is so important. If I’m working on the least good solution, I might want to to stop that, pick up where my colleague is going and see if I can help him push the accuracy up a few more points.”
Dotscience’s platform will be available in August as a software-as-a-service (SaaS), software that be deployed on-premise or through the Amazon Web Services (AWS) Marketplace. Flexibility is a key element. It can work with data from files stored on the platform, in remote object storage places such as S3 or S3-compatible environments, Microsoft Azure or Google Cloud Platform, and in SQL, NoSQL and Spark data lakes, and workloads – from code to data to hyperparameters – can easily be moved from one system to another between the cloud and on-premises datacenters. The platform also works with machine learning framework for Python, from PyTorch and Caffe to Apache MXNet and Theano.
Dotscience sees a significant opportunity to gain traction in a fast-growing market. Coleman noted that total addressable market by 2025 will be around $100 billion, with the serviceable address market being about $50 billion. The company also is targeting a range of sectors, from financial tech and autonomous vehicles to healthcare, financial services and insurance. It also is eyeing a range of competitors, including the open source KubeFlow platform developed by Google “because we’ve seen the massive growth of Kubernetes and with KubeFlow, that’s the same sort support and that’s become quite interesting quite soon,” Coleman says. Other competitors include such vendors as DataRobot and Domino Data Lab, both of which offer data science and machine learning platforms.
“They seem to be very well-funded and they’re moving in a similar area in that they are approaching it holistically,” he says. “But I think the way we differentiate that is really around the strong interest in provenance. I think they’ve got the end-to-end in, but perhaps lack some of the deep integrations to make sure that everything is trackable. It’s a fast-moving market, so you don’t know what’s going to happen in six months.”


Expanding DevOps With Infrastructure As Code
The hyperscalers have taught us many lessons in the past two decades, and one of them is that everything that can be defined in software should be so that it can be controlled automatically and programmatically – and that goes double for hardware, which has required so much human babysitting …
Inside Tesla’s Innovative And Homegrown “Dojo” AI Supercomputer
How expensive and difficult does hyperscale-class AI training have to be for a maker of self-driving electric cars to take a side excursion to spend how many hundreds of millions of dollars to go off and create its own AI supercomputer from scratch? And how egotistical and sure would the …
HPE Creates Its Own AI Stack For Large Enterprises
While the hyperscalers have been running AI workloads against vast datasets in production for a decade and a half, many large enterprises have lots of data they think is relevant but they are not at all experiences with AI and the system requirements it has. That’s where companies like Hewlett …
Be the first to comment