

If the ARM processor in its many incarnations is to take on the reigning Xeon champ in the datacenter and the born again Power processor that is also trying to knock Xeons from the throne, it is going to need some bigger vector math capabilities. This is why, as we have previously reported, supercomputer maker Fujitsu has teamed up with ARM holdings to add better vector processing to the ARM architecture.
Details of that new vector format, known as Scalable Vector Extension (SVE), were revealed by ARM at the Hot Chips 28 conference in Silicon Valley, and any licensee of the ARMv8 architecture will be able to add these features to their chips once the specification is ratified, and vendors making ARM chips will have a native way to do vector math that presumably will be more competitive with vector engines on Xeon and Power processors and certainly a lot better than the NEON SIMD engines that have been an option for ARM chips for a dozen years.
As Nigel Stephens, an ARM Fellow and the lead ISA architect at the chip designer, put it in his presentation, the NEON math units, which debuted with the 32-bit ARMv7 architecture and which were also known as the Advanced SIMD instructions, were just not going to cut it. The NEON units supported single-precision (32-bit) integer, fixed point, and floating point calculations, with the floating point not being up to IEEE snuff; it had 16 128-bit vector registers in its initial implementation with ARMv7. With ARMv8, which shifted the processing to 64 bits, the NEON units evolved with the addition of 64-bit integer vector operations as well as full IEEE-compliant double-precision (64-bit) floating point math; the vector registers grew to 32 by 128 bits. But NEON was really still aimed at accelerating various media processing and was not really tuned specifically for running the kinds of calculations in a scientific simulation or machine learning application.
With the ARMv8 chasing new architectures – and in particular getting some footing in the HPC space in Europe, China, and Japan – Stephens and his team at ARM wanted to have a new vector architecture that was a bit more radical and would last for a long time. Specifically, they determined that this SVE approach would need to support gather load and scatter store operations, have per lane predication, and support even longer vectors so that more fine-grained parallelism could be extracted from the processor (and not have to be offloaded to a GPU or DSP or FPGA coprocessor). But the issue was, how long do you make the vectors?
“The ARM architecture covers a wide range of implementations,” explained Stephens, “from very small, high efficiency designs to very large high performance designs, and each of these needs to make different tradeoffs in their design. The vector length is a big part of that, and that is the tricky part. What are we going to do? ARM’s conclusion is that there is no preferred vector length for the architecture. Instead, SVE makes the vector length a hardware choice for the CPU designer, allowing it to be anywhere from 128 bits to 2,048 bits in 128 bit increments.”
The SVE approach also introduces a programming model that is agnostic with regard to vector length, which allows the software to be written in such a way that it can adapt to the vector sizes in a given chip without requiring a recompile. (Or, in the cases where programmers hand-code the software, they also will not have to rewrite it.) Importantly, as the vector length increases in the hardware, the SVE approach will allow this code to continue to scale across the vectors in the hardware as they elongate and shorten. (By the way, SVE is a completely new set of vector instruction encodings that is distinct from and not related to the Advanced SIMD instructions used in the NEON vector units.)
Just having bigger vectors is not enough, of course, and if it were that simple, ARM would have added bigger vectors aimed at HPC workloads already to the ARMv8 architecture.
“It is all very well having huge vectors – that’s great – but Amdahl’s Law tells us that a task’s potential speedup is really governed not by the vectors but by the size of its unvectorizable parts,” Stephens elaborated. “And compilers are all too often unable to vectorize the important loops in a program, which leads that big, wide vector unit underutilized and failing to provide the performance that people expect.”
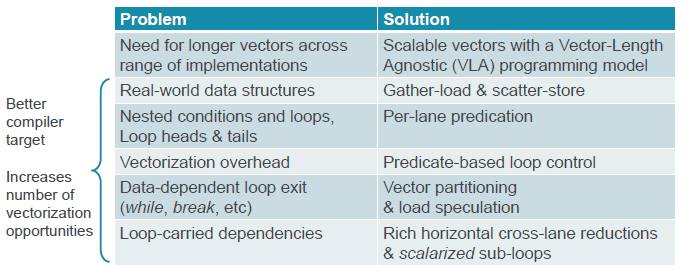
To that end, SVE has auto-vectorization features, which will be able to sift through code looking for parallel loops that can be pushed through on-chip vector units. (Our colleague Chris Williams over at The Register has an excellent explanation of how this auto-vectorization works.)
ARM managed to cram the SVE instruction set into a 28 bit region of the architecture, which Stephens said was quite a feat of engineering. The SVE instructions only work with the 64-bit AArch64 architecture embodied in the ARMv8 designs and will not work with the AArch32 architecture of the ARMv7 and earlier designs. The SVE vector feature can handle C, C++, and Fortran data types as well as floating point, integer, and logical operations; it does not support fixed point and DSP/media operations like the NEON vector units did, which by the way are still part of the architecture and still can be added to a chip if designers want to have both HPC and media processing on the same chip.
The underpinnings of SVE are quite complex, but the upshot is that the ARM architecture will have features that allow ARM chip makers to put a lot of vector oomph into their designs – something that has been lacking and something that Fujitsu must have demanded on behalf of the Post-K exascale supercomputer that it is building for RIKEN on behalf of the Japanese government.
To give a sense of how much better SVE vectors are for HPC workloads compared to NEON vectors, Stephens show the following chart, which shows the increase in the vectorization of various HPC codes and the level of speedup when pushing that increased vectorized code through an SVE unit with 2,048-bit vectors:
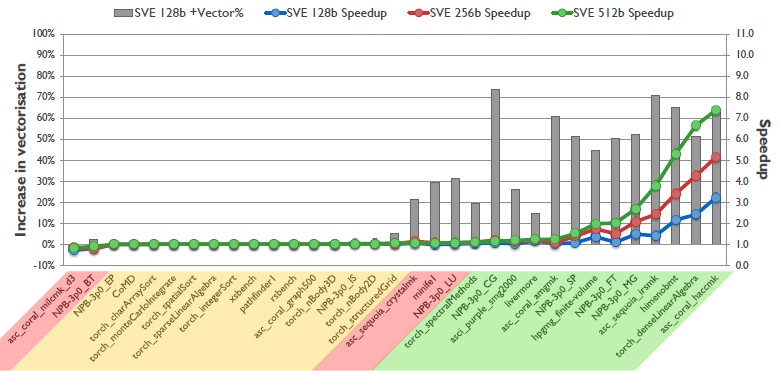
As you can see, many of the HPC codes tested by ARM using simulators for both SVE and NEON do not see any increased vectorization and performance boost at all, while those on the right of the chart show increasing vectorization and performance speedups, particularly as the vectors get increasingly large in terms of their bitness. The 512-bit limit is significant because Fujitsu has chosen a 512-bit length for the ARM-based processor to be used at the heart of the Post-K machine; longer vectors are possible and would presumably show an even larger speedup than is shown for certain applications.
“There is clearly work to do here, it is early days,” Stephens said of the initial performance estimates, and what we really want to know is how SVE will stack up against vector units in Xeon and Xeon Phi processors from Intel and from Power processors from IBM. “Major code issues still exist, and those in the red on the chart do not scale that well. But it shows a lot of potential.”
Stephens said there are multiple partners working on SVE, with Fujitsu and RIKEN being the one announced and we think the Chinese government being another one not yet announced formally but we have heard that China has an exascale system coming based on ARM so it stands to reason the teams behind this machine at the National University of Defense Technology know about SVE and are implementing it in their processors, too. (It may or may not be a CPU-DSP hybrid.)
Support for SVE will start being rolled into various open source projects within a matter of weeks, starting with the Linux kernel and the KVM hypervisor, as well as the GCC and LLVM compiler stacks and related tools. The SVE specification will be done by late 2016 or early 2017, including an architectural overview, C and C++ intrinsics, and an application binary interface changes needed for the ARMv8 architecture.

Arm Neoverse Roadmap Brings CPU Designs, But No Big Fat GPU
Spoiler alert! A lot of neat things have just been added to the Arm Neoverse datacenter compute roadmap, but one of them is not a datacenter-class, discrete GPU accelerator. And another one that is also not there is a more specific matrix math accelerator like the ones that Intel (well …

Fujitsu Cloud Service to Put Fugaku Supercomputer in Reach
For those looking to try out Fujitsu’s Arm-based PRIMEHPC FX1000 system, the company is opening up the same capabilities via its own cloud service. Access to the Fujitsu A64X-based systems, which are at the heart of the top-ranked Fugaku supercomputer in Japan, will begin in October in-country, with global rollout …

Taking A Superhybrid Approach To HPC/AI Convergence
AMD has been on such a run with its future server CPUs and server GPUs in the supercomputer market, taking down big deals for big machines coming later this year and out into 2023, that we might forget sometimes that there are many more deals to be done and that …
It would be very interesting to see a detailed article on NEC’s new vector architecture. I heard that they’re switching from their pure vector SX-ACE type chip and incorporating x86 somehow.
Its interesting that the SX-ACE is the last real vector architecture that I know of, but it rarely gets mentioned anywhere. The Earth Simulator is now in its third iteration with 1.3 PFLOPS and 1.3PB/s using SX-ACE nodes.
I wonder if there will be an Earth Simulator 4 using the new “NEC Aurora” architecture(not to be confused with the Cray Shasta Aurora)?