

For the first time since the Top 500 rankings of the most powerful supercomputers in the world was started 23 years ago, the United States is not home to the largest number of machines on the list – and China, after decades of intense investment and engineering, is.
Supercomputing is not just an academic or government endeavor, but it is an intensely nationalistic one given the enormous sums that are required to create the components of these massive machines, write software for them, and keep them running until some new approach comes along. And given that the machines support the militaries and indigenous industry in their home countries, there is always politics in play. The competition between HPC centers in the United States, China, Europe, and Japan is to be expected and is, in a sense, a reflection of the larger economic reality on Earth.
China has had the most powerful machine on the list before, starting with the Tianhe-2 system at the National Supercomputer Center in Guangzhou province that was built by the National University of Defense Technology, which is a hybrid Xeon-Xeon Phi machine that came in at the top of the list in June 2013 with a 33.86 petaflops rating on the Linpack HPC system performance benchmark. The Tianhe-2 machine has remained in that top spot for the past three years, but today has been knocked from its perch by a new – and unexpected – machine called Sunway TaihuLight that was built for the National Supercomputing Center in Wuxi by the National Research Center of Parallel Computer Engineering and Technology, which has a peak theoretical performance of 125.4 petaflops and that delivered a sustained 93 petaflops on the Linpack test.
We have drilled down into the details of the Sunway TaihuLight system separately, but back when Tianhe-2 was announced in June 2013, there were many people who said that system was a stunt machine, something that the Chinese government had put together because it could afford to do so and it wanted to beat the top of the list.
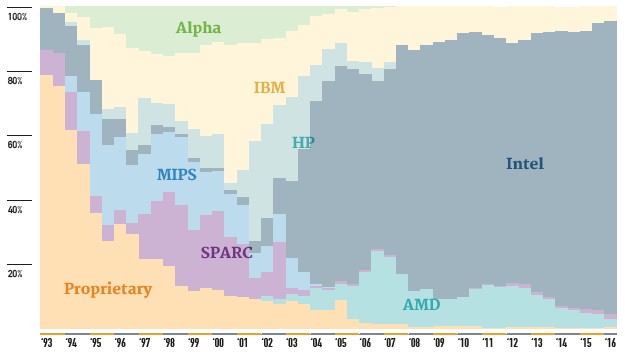
As far as we can see, the Sunway TaihuLight system is a real machine with its own architecture, including an innovative processor design based on the Sunway (sometimes spelled ShenWei) RISC processor that has been in development for the past decade. There are many that speculate that the Sunway processor is based on the Alpha 21164, a RISC chip developed by Digital Equipment for its AlphaServer systems over two decades ago, but this has never been confirmed and often denied. As far as we know, there have been three prior generations of ShenWei processors, and there could have been more developed behind the scenes at Wuxi. The ShenWei SW-1 was a single core chip from 2006 running at 900 MHz, the SW-2 had two cores topping out at 1.4 GHz, and SW-3, also known as the SW1600, had sixteen cores running at 1.1 GHz. The Sunway TaihuLight supercomputer that was unveiled as the most powerful system on the June 2016 Top 500 rankings uses the SW26010 processor, which has a total of 256 compute cores and another four management cores all on a single die, running at 1.45 GHz. The system has a whopping 40,960 nodes for over 10.6 million cores, which share over 1.31 PB of memory.
It stands to reason that the Sunway TahuLight machine will be ranked number one on the Top 500 list until the “Summit” system built by IBM, Nvidia, and Mellanox Technologies for the US Department of Energy’s Oak Ridge National Laboratory comes online in late 2017 if all goes well, perhaps with around 150 petaflops of peak performance across its 3,500 nodes. The Summit machine will be comprised of multiple 24-core Power9 processors, an unknown number of “Volta” GV100 Tesla coprocessors, and a 200 Gb/sec HDR InfiniBand interconnect. The expectation is that the “Aurora” system based on “Knights Hill” Xeon Phi processors from Intel and going into Argonne National Laboratory, will surpass Summit in 2018, with a rating of around 180 petaflops across more than 50,000 nodes.
That is a long time to wait for the United States to be back on top of the list in terms of performance, and unless some of the hyperscalers and cloud builders start running the Linpack benchmark on their biggest clusters, as myriad Chinese companies have done, then it seems unlikely that the United States will take the lead again in system count. This, ironically enough, could actually help spur more funding in supercomputers in the United States and foster more investment in Europe and Japan, too.
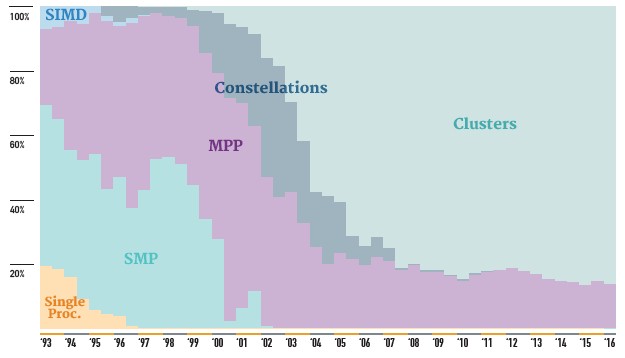
On the current list, China has 167 machines on the Top 500 list, up from 109 machines only six months ago when a burst of activity gave it that number. As the Chinese machines came onto the list as Internet companies ran Linpack on their gear, they knocked other systems off the list, and as a consequence there are only 165 systems on the June 2016 list that call the United States home, down from 233 machines a year ago and 256 two years ago. It has been a long time since the United States did not have at least half the machines on the list – the early 2000s, in fact. And the level now is even lower. There are 105 machines on the June 2016 rankings that are on European soil (about the same as last year), with Germany having the most with 26 systems, France with 18 machines, and the United Kingdom with 12 machines. China is pulling up the Asian class average on the Top 500, but Japan saw its count drop from 37 six months ago to 29 machines on this ranking.
The most powerful system in the United States that has run the Linpack test is the “Titan” supercomputer at Oak Ridge, built by Cray and using a mix of 16-core AMD Opteron 6274 processors and Nvidia Tesla K20X GPU accelerators, linked by its “Gemini’ interconnect, to deliver its 17.6 petaflops of sustained performance on the Linpack benchmark. Titan was the number one ranked machine when it was first tested for the November 2012 Top 500 list, and seven months later was knocked to the number two position by Tianhe-2 and now to the number three spot by Sunway TaihuLight.
The “Sequoia” BlueGene/Q system at the US Department of Energy’s Lawrence Livermore National Laboratory, which represents the culmination of the BlueGene massively parallel design by IBM, has 1.57 million cores running at 1.6 GHz and a custom 3D torus interconnect to deliver 17.2 petaflops of Linpack oomph, and its Mira sister, installed at Argonne, has about half as many cores and about half the performance at 8.59 petaflops. Sequoia was partially built and ran Linpack for the November 2011 list and came in first for only one ranking, back in June 2012. It has been dropping as Titan, Tianhe-2, and Sunway TaihuLight were installed and tested, and Mira has mirrored its moves downwards on the list.
Between these two machines is the K supercomputer made by Fujitsu for the Riken Advanced Institute for Computational Science in Japan, which is rated at 10.5 petaflops and uses a Sparc64-VIIIfx processor with eight cores that run at 2 GHz and the custom Tofu 6D interconnect. This machine, by the way, remains one of the most efficient machines to run the Linpack test and it was installed more than five years ago.
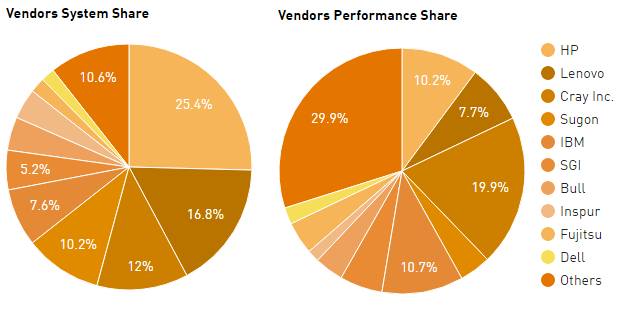
The remaining four machines in the Top 10 of the Top 500 are all built by Cray and all use its current “Aries” interconnect. The “Trinity” system shared by Los Alamos National Laboratory and Sandia National Laboratories, is a Cray XC40 system that uses 16-core “Haswell” Xeon E5-2698 v3 processors and delivers 8.1 petaflops, while the “Piz Daint” is an XC30 that has a mix of eight-core Xeon E5-2670 processors and Nvidia Tesla K20X GPU accelerators to hit 6.27 petaflops on the Linpack test. The “Hazel Hen” system at Höchstleistungsrechenzentrum Stuttgart (HLRS) in Germany is ranked ninth on the list, with 5.64 petaflops of sustained Linpack oomph and uses twelve-core Xeon E5-2680 v3 processors to do it computations. The Shaheen II supercomputer at King Abdullah University of Science and Technology in Saudi Arabia is configured with 16-core Haswell Xeons like Trinity, but has fewer of them and comes in at 5.54 petaflops.
The capability-class machines that have been on the list for four or five years might be a little long in the tooth considering that supercomputing centers like to have a new machine every three or four years, but they are showing longevity and continued usefulness. And considering that the largest machines tend to cost on the order of $200 million a pop, wanting to squeeze extra work out of them seems only natural. (Upgrade deferrals a common everywhere in IT, except perhaps at the hyperscalers that seem to have nearly infinite money to invest in new infrastructure.) But at some point, HPC centers, which by definition exist to push the boundaries of system architecture, need new machinery and new software investment to make it hum.
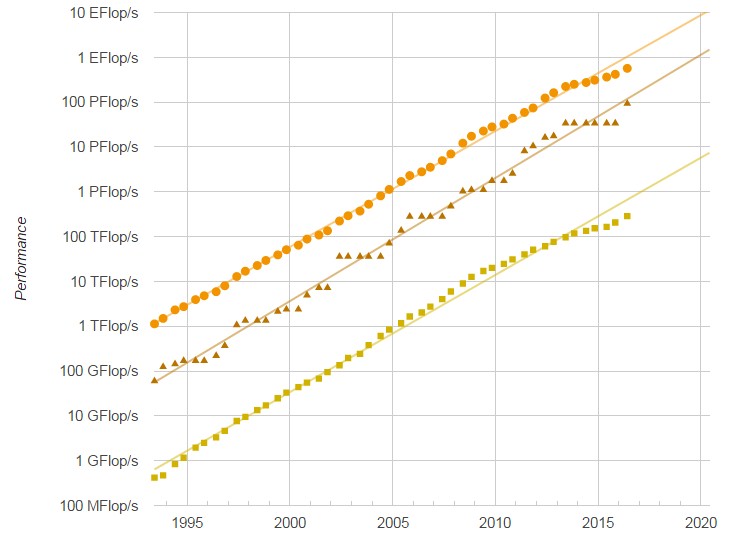
This is why the performance of the largest machines on the Top 500 list and the aggregate oomph of the machines that comprise the entire list keeps growing. But as we have pointed out before, the pace of that growth is slowing and we think that one of the reasons is that the cost of a unit of performance is not coming down as fast as performance is going up. If you do the math, performance is increasing for the biggest supercomputers four times faster over the past four decades than the bang for the buck for these machines is increasing.

The number of petaflops-class machines continues to grow, thanks to Moore’s Law advances in compute engines and interconnects, and there are now 95 machines with more than 1 petaflops of sustained Linpack performance, up from 81 six months ago, 68 machines a year ago, 37 machines two years ago, and 26 machines three years ago. Putting together a petaflops-scale system has certainly gotten both easier and more affordable, but we wonder if there is more elasticity in demand and that if the price were dropped, would demand increase at a faster pace? The mitigating factor, of course, is the cost of building facilities and paying for the electricity to power and cool these behemoths. If energy was free, or even close to it, this market would look very different indeed. And, by the way, so would enterprise datacenters and hyperscalers.
The thing is, however, that the performance of the aggregate Top 500 list continues to grow, even if it is at a slower pace. On the June 2016 list, all of the machines added up to a combined 566.7 petaflops, which is up from 363 petaflops a year ago, 274 petaflops two years ago, and 223 petaflops three years ago. The concurrency in the systems – the number of cores that are shared across clusters and MPPs and such – keeps rising, too, hitting an average of 81,995 this time around compared to an average of 50,495 a year ago, 43,301 two years ago, and 38,700 three years ago. The big machines near the top of the list, which have millions of cores and soon will have tens of millions, are pulling up the class average, and will continue to do so.
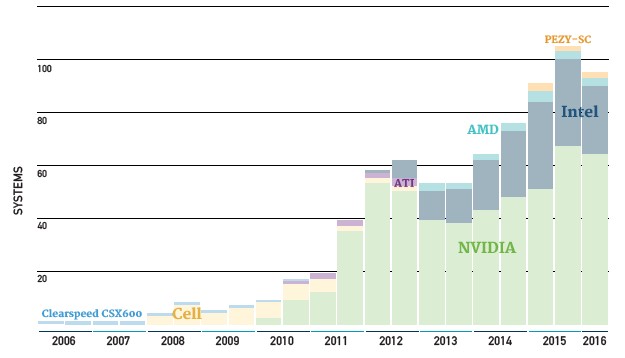
The other interesting thing to note is that the number of accelerated machines dropped slightly, to 93 systems from 104 machines on the November 2015 list. The Nvidia Tesla business unit has been growing sales quite rapidly, so it is a bit perplexing why the Top 500 list doesn’t reflect this. Revenues are not shipments, we realize, and the hyperscalers doing machine learning are driving a lot of that Tesla business, and perhaps so are a lot of smaller clusters than can’t make the Top 500 list. It will be interesting as well to see what the split will be between Xeon and Xeon Phi systems, and if many of the will end up being hybrid systems within a single cluster instead of hybrid by mixing CPU and GPU inside of cluster nodes. (We report on Nvidia’s latest “Pascal” Tesla coprocessors separately today, which plug into regular PCI-Express slots but which do not support NVLink interconnects.)
There are no doubt a bunch of machines that never run the Linpack test and therefore never make the list – the “Blue Waters” hybrid CPU-GPU supercomputer built by Cray for the National Center for Supercomputing Applications, which has a peak performance of over 13 petaflops, was the first big machine we heard of that did not run Linpack. So while the list is illustrative of technology trends and helps drive competition among vendors that make systems and countries that invest in them, it is not a fully complete ranking of HPC systems. And it would be better for everyone if it were.


Real-World HPC Gets the Benchmark It Deserves
While nothing can beat the notoriety of the long-standing LINPACK benchmark, the metric by which supercomputer performance is gauged, there is ample room for a more practical measure. It might not garner the same mainstream headlines as the Top 500 list of the world’s largest systems, but a new benchmark …

Dennard Scaling Demise Puts Permanent Dent in Supercomputing
When the TOP500 list of the world’s most powerful supercomputers comes out twice a year, the top-ranked machines receive the lion’s share of attention. It is, after all, where the competition is most intense. But if people had given more scrutiny to the bottom of the list, they would have …
The Widening Gyre Of Supercomputing
The twice-annual ranking of distributed computing systems based on the Linpack parallel Fortran benchmark, a widely used and sometimes maligned test, is as much a history lesson as it is an expectation always looking forward, with anticipation, to the next performance milestones in high performance computing. As we have pointed …
I’m not surprised at this. With our government controlled by anti-science politicians this was inevitable that the United States would fall behind in this category, I wonder what’s next?
No China just threw a lot of CPU cores at the problem! Now just what new Nuke Plant will be powering this system.
And Now Japan(1) throws in for a Thousand of those Petas with an ARM Based system, and I do wish the Press would let the reads know if Fujitsu is using some ARM Holdings reference core designs or if Fujitsu has gone with a Top Tier ARMv8A ISA architectural license and will be rolling their own custom micro-architecture engineered to run the ARMV8A ISA?
It’s really imperative that the technical press differentiate designs based on Arm Holdings reference design ARM cores from the Custom Designs that are engineered to run the ARMv8A ISA, as those custom designs are very different under the bonnet. I hope that there will be more attention paid to just what AMD’s custom K12 ARMv8a ISA based designs may be bringing to the custom ARMv8A ISA running marketplace, after the news of what Fujitsu is planning.
There needs to be more writing of primers to educate the readers on the differences between ARM holding’s reference designs and the Custom design ARMv8A ISA running designs, with some of the custom designs being more similar to a Desktop/Laptop SKU. There needs to be more journalistic digging and reporting on the different custom designs’ CPU core execution resources, and that includes creating reader accessible specification sheets and tables for reader reference when discussing such custom ARM based silicon. It upsets me to no end that both Intel’s and AMD’s custom x86 ISA running implementations are discussed in great detail, Power8s/power designs likewise, but the many ARMv8A ISA running custom micro-architectures are treated poorly by the press when it comes to any CPU core architectural deep dives.
(1)
“Fujitsu picks 64-bit ARM for Japan’s monster 1,000-PFLOPS super”
http://www.theregister.co.uk/2016/06/20/fujitsu_arm_supercomputer/
I know they threw a lot of cores at their new system but I’m referring to the bigger picture in that our esteemed congress has more than a few key people in positions that control spending on scientific projects. We now have the most anti-science congress in American history, this does not lead to spending on government HPC systems for scientific research. This is what I am referring to not China’s new system specifically.
Rob has a point of view dammit! And he is going to make the “facts” fit his point of view whether they do or not!
I am working on it. Fujitsu is going to be doing its own cores. I know that much, and tuned for HPC like the Sparc64 fx chips were.
Let’s see how wide order superscalar of a micro-architectural custom design that Fujitsu can bake up to run the ARMv8A ISA! My money is on AMD’s K12 for possibly having a custom ARMV8A running micro-architecture with some SMT ability baked in! Simultaneous multi-threading on a custom ARMv8A running micro-architecture and a wide order superscalar design like IBM’s Power8 is what is needed, and the ARMv8A ISA is a RISC design, as is the Power ISA.
So let’s create a Custom ARM knowledge base, and try to get at every little bit of the custom ARM Core market’s every little detail, with info like numbers of instruction decoders, reorder buffer sizes, pipeline stages, cache memory hierarchies and caching algorithms implemented, etc. You Know all those nice CPU core block diagrams that reveal the underlying CPU core execution resources for all the custom ARM designs so readers can compare and contrast the various custom micro-architectures engineered to run the ARMv8A ISA.
Arm Holdings itself should be investing in getting a really fat wide order superscalar reference ARMv8A ISA running design with SMT capabilities that it could job out to those without the CPU design engineers to do it themselves, so maybe there can be some more low cost home ARM based server choices for the Mom and Pop types of businesses. With the Power8/Power micro-architecture as a shining example of just how far and wide order superscalar, and SMT enabled, a RISC ISA based design can be taken, it should be a no brainier to see that very same potential exists for any of the custom ARMv8A ISA running designs, should the various top tier ARM architectural licensees choose to invest the time and resources, including ARM holdings itself.
Apple sure did up a nice custom treatment with its Apple A7-A9 series of custom designs, with the A7 being the first product engineered to run the ARMv8A ISA on the market, beating even ARM holdings to market in using ARM Holdings’ very own 64 bit RISC ISA. Well ARM holdings has very little to worry about as it still gets the licensing/royalties from every ARM/ARM ISA running chip sold, reference or custom designs by the billions.
ARM holdings does need to get maybe a good server reference design of its own, and maybe even go for a Laptop/netbook capable ARM holdings Reference core design that is fat like the Apple A7 and can be paired with that new Mail/bifrost, and related IP. Apple needs to look at adding SMT capabilities to its custom ARM core designs, before it even thinks about adding more cores, ditto for ARM Holdings with some future netbook and server reference designs. SMT capabilities can get a little more IPCs out of a CPU core design and better CPU core execution resources utilization metrics by working one processor thread while the other thread is stalled and waiting for a dependency/memory or cache access latency to complete.