

Having made the improbable jump from the game console to the supercomputer, GPUs are now invading the datacenter. This movement is led by Google, Facebook, Amazon, Microsoft, Tesla, Baidu and others who have quietly but rapidly shifted their hardware philosophy over the past twelve months. Each of these companies have significantly upgraded their investment in GPU hardware and in doing so have put legacy CPU infrastructure on notice.
The driver of this change has been deep learning and machine intelligence, but the movement continues to downstream into more and more enterprise-grade applications – led in part by the explosion of data.
Behind this shift is an evolving perspective of how computing should operate— one that has a particular emphasis on massive quantities of data, machine learning, mathematics, analytics and visualization. These forces have exposed the shortcomings of the CPU while highlighting the attributes of GPUs and signal a key inflection point in computing that will ultimately permeate every enterprise, from technology giants to the local credit union.
The demise of Moore’s Law is a subject of open debate in the semiconductor industry. While the “law”, which states that number of transistors in a dense integrated circuit doubles approximately every two years, has performed for decades, it has hit a bit of a wall in recent years. The first problems began to appear a decade ago when CPU manufacturers hit the “clock wall” – keeping processor speeds under 4GHZ for close to a decade now.
The talented engineers at Intel and AMD overcame this problem by adding more cores per processor— each with more instruction-level (superscalar) and data-level (SIMD) parallelism.
Adding more cores has its own implications as noted by programmer Herb Sutter in his famous 2005 essay “The Free Lunch is Over”. The point Sutter made is that the large single-threaded performance gains software developers had grown accustomed to were a thing of the past and programmers were being forced to increasingly parallelize their code to take advantage of multicore processors.
The net effect was to limit computing progress at a time where more compute was needed. The subfields of Artificial Intelligence (machine learning, computer vision, natural language processing, topology) required the capacity to consume and render large datasets – tasks CPUs simply are not effective at delivering. The standard answer was to add more CPU compute, but this has significant costs, costs that include power, cooling and maintenance.
Faced with these challenges, a handful of pioneers began to work with GPUs to leverage the distinct capabilities of these X-Box and Playstation oriented computing platforms.
The Graphics Processing Unit was initially designed to project polygons onto a user’s screen – often in the form of zombies, athletes, aliens and racecars. As the gaming industry grew, so did the appetite for performance.
GPUs eschewed the high clock speeds and architectural complexity required for high single-threaded performance demanded by CPUs. Rather, GPUs achieved massive parallelism by combining thousands of relatively simple processing units to perform the math required for polygon rendering.
While not optimal for many general purpose computational workloads— for example powering a word processor— GPUs excel at tasks requiring large amounts of arithmetically intense calculations, such as visual simulations, hyper-fast database transactions, computer vision and machine learning tasks.
As a result, the ranks of the world’s top supercomputers have come to be dominated by systems deriving most of their computational power from GPUs and similar devices (such as the Intel Phi). To fully appreciate the difference in CPU vs. GPU look at this slide from the GPU Technology Conference Keynote this year:
Because of the massive performance differences, GPUs have made the jump from their origins in gaming and scientific computing to a far larger swath of the computational spectrum— seemingly overnight as evidenced in this Nvidia slide:

The large matrix computations involved in many machine learning algorithms are a natural fit for the mathematical prowess of GPUs. In particular, GPUs are front-and-center in the rapidly developing field of deep learning, which harnesses networks of artificial neurons reminiscent of the human brain to achieve best-in-class performance at all sorts of classification tasks such as recognizing objects in images (autonomous vehicles) and parsing speech.
While machine learning and cognitive computing are expected to be massive markets (IBM sees Cognitive Computing as a $2T opportunity) there are dozens of additional markets, some larger still, that are well suited for this new class of computing: everything from virtual reality to self driving cars, from the Internet of Things (IOT) to advanced analytics.
Advanced analytics is a particularly fertile field because it demands speed and rendering.
Broad by design, advanced analytics encompasses databases, BI, visualization and statistics, has long been the domain of CPU-based solutions. But that seems poised to change.
The reasons are two-fold. First, the rise of massive data lakes have created truly giant datasets. Second, these massive data lakes have exposed the computational inadequacies of even the “fastest” database solutions.
Together, the two have created a major obstacle for the future of BI and Analytics: query time.
If you want to run a query against a billion or more records (pretty common), with today’s legacy database solutions you should plan a two martini lunch— because that’s how long it’s going to take to run.
You better have your question nailed too, because if you want to modify it, well, you are going to dinner before you see the updated query again.
The experience is similar to the days of dial-up page load times, which, wouldn’t that problematic if we didn’t know what real speed felt like.
Indeed, if speed is the goal, the only answer with legacy solutions is to take data off the table— say 900 million rows. This is referred to as downsampling and it is the standard response to the prospect of waiting.
This, by definition, produces a suboptimal outcome. Was your sample representative? Was there bias in the selection process? Is there a critical feature in the data that now goes undetected?
In a world where performance maintains a premium, technology wave after technology wave, working on outdated CPU infrastructure is a losing proposition.
This is why GPUs are going to have such a major impact on the enterprise. Because with the right combination of hardware and software, that billion row query comes back in milliseconds.
The process of discovery becomes fluid, creative even.
A data discovery process that is fluid and creative lends itself to better outcomes – outcomes that allow analysts and business users to collaborate in real time, to brainstorm, to ask questions freely as opposed to waiting for answers.
The cost to make such a query also comes down considerably.
Analysts and data scientists are finite resources with real costs associated with them. Enabling them to work more productively, more collaboratively, more fluidly has significant ROI implications. Further, a single GPU server can do the work of 20-40 CPU servers but with less hardware, energy, real estate and maintenance/support. Together, the total cost of ownership equation tilts dramatically in favor of GPU computing – both in terms of the capacity utilization of some of your most valued employees and the physical costs of running more efficient hardware.
For a large organization it will easily run to the millions of dollars per year.
To put this is context, let’s consider an example from the booming IOT market. In the IOT world, billions of sensors (Intel thinks that # will be 200B by 2020) will produce millions of records each.
Within that data lie the answers to uptime, network health, risk mitigation and product development.
GPUs make that data accessible in real time.
One of our clients, a giant US wireless carrier, polls every smartphone in the network to determine the status of the device, the health of the signal and the performance of the network.
Needless to say this is a large number of records.
Previously, this would take hours to run and hours more to analyze on their considerable . As a result, they did it periodically, often overnight.
Now the carrier does this task in real time and that changes the game considerably. The team can interact with the data, respond immediately to executive and operational inquiries and use those insights to develop predictive models.
GPUs lie at the center of this success story. They enable the real time responsiveness— something that legacy CPU driven solutions cannot deliver (and keep in mind this is one of the largest wireless companies in the world— they were investing heavily in hardware and software.
While GPUs sit at the center of the availability equation it will be software that unlocks their speed. That is where companies like MapD and others come to play and why Nvidia is so committed to building out the application eco-system to bring GPUs to the enterprise.
GPUs deliver better performance for many of the tasks that will define the enterprise going forward and it is why the most innovative companies are pivoting to that direction. Still, for GPUs to proliferate in the enterprise, a new class of software will be required to harness the compute power and promise of the GPU era. This next wave of software development will leverage the significant developments achieved in machine learning over the past number of years and will fundamentally accelerate the pace of technological change.
This is why GPUs are rapidly becoming the weapon of choice in datacenters and cloud service providers and why there is a race to develop the software to harness, optimize and leverage this extraordinary compute resource.
Every wave of computing has an inflection point. For the intelligent enterprise, GPUs are that inflection point. Welcome to the golden age of intelligent computing.
About the Author
Todd Mostak is CEO of GPU database company, MapD. We profiled the company’s GPU accelerated database back in March as it awaited the “Pascal” Tesla accelerators from Nvidia.


The GPU Database Evolves Into An Analytics Platform
As the name of this publication suggests, we are system thinkers and we like to watch the evolution of a collection of tools into a platform. That’s the neat bit, when all the propellerheads have done the work on the components and the integration and when those tools can be …
MapD Fires Up GPU Cloud Service
In the long run, provided there are enough API pipes into the code, software as a service might be the most popular way to consume applications and systems software for all but the largest organizations that are running at such a scale that they can command almost as good prices …

Crunching Machine Learning And Databases Together On GPUs
While it is always best to have the right tool for the job, it is better still if a tool can be used by multiple jobs and therefore have its utilization be higher than it might otherwise be. This is one of the reasons why general purpose, X86-based computing took …
One new MapD business line could sell an appliance acting as Tableau/Qlick/Microstrategy/etc accelerator.
Well said. One underlying technical point driving this transformation is trend from disk-based to in-memory processing. NVIDIA’s HBM2 memory on the new Pascal architecture has 720 GB/s bandwith, approximately 10X faster than main system memory.
This article helps explain why GPUs are catching on for databases and graph analytics – areas that are not “compute intensive” and were not previously associated with GPU accelerators.
GPU and especially nVIdia have a pretty bad history when it comes to power to performance ratio and definitely do not scale down very well. So I beg to differ that we are going to see in the future are more flexible silicon architecture that can be optimized on their perf/W. And GPU aren’t that.
GPU performance per watt beats anything that any CPU could ever hope to provide, just look at the level of parallelism that the modern GPU provides and at a lower clock speeds relative to any CPU, even Intel’s Xeon phi! Just look at the massive ranks and files of GPU cores and that GPU gigaflops per watt metric and see that no CPU’s paltry amount of higher clocked execution units, and more power wasting higher clocks at that, will never approach the efficiencies of any make of GPU from the many makers of Mobile/desktop GPU SKUs!
Look at the ultra high cost of any “High core count CPU” and there in lies the beauty of the GPU for any and all types of number crunching.
CPUs are the Mooks of the number crunching world, and there will never be and Exaflop rated computer that uses CPUs alone, as it has been for the petaflop computers! And only just recently when reaching on down into a level of the Teraflop(single digit)/GigaFlop level of computing for some CPU only systems able to get into the the gigaflop/teraflop range through using relatively “Many” CPU cores. And That “Many” CPU cores to get into the Teraflop range of FP performance is in relative terms not many cores at all for the GPU, and that includes GPUs from a good while ago also, GPUs have those cores by the Hundreds/Thousands, at a much more affordable core per dollar ratio than any CPU can provide.
I’d expect that very shortly the there will be even more CPU like functionality in store for AMD’s ACE units! Also for Arm Holdings well as, and ARM’s Newest Mali-G71 Bifrost micro-architecture SKUs, that have just gone over from a VLIW/instruction level parallelism based design to a more asynchronous compute thread level parallelism based GPU ISA design, to allow for a more CPU asynchronous compute like thread level of Instruction dispatch/context switching/scheduling on the G71’s GPU core execution units. So those “Clauses” on ARM’s newest GPU micro-architecture can have related instructions pre-vetted of any dependencies and grouped into Clauses of instructions that can be scheduled and preempted and split to hide latency while allowing other unrelated clauses to be context switched in to make for much more efficient GPU execution resources utilization. GPUs are getting a lot more of the CPU like levels of logical control over the thread level of execution/scheduling with each new generation, so even more of the demanding levels of AI types of functionality can be done on the GPUs execution engines/processing units.
Watch out for the GPU Intel, and watch out for the APU on an Interposer designs from AMD even more, Chipzilla(CPU Chip lumbering beast), as those APUs on an interposer designs are going to marry the Zen cores up to the Many more GPU cores via some very wide interposer etched coherent fabrics! And coherent fabrics that no PCI/Nvlink narrow interconnect will match for raw CPU/Cores to fat GPU die interconnect fabric total effective raw bandwidth in the Terabytes per second range. The CPUs of the future will mostly be relegated to computing system janitorial duties, while the GPU crunches the numbers and even does some of the more demanding AI workloads, other acceleration tasks, in addition to those graphics uses!
Mea Culpa, on this post/reply!
“as it has been for the petaflop computers!”
needs: it had been for petaflop computers!
also needs clarification for CPUs only for ExaFlop computing coming in under the exascale computing initiative’s power budget for an ExaFlop rated computer’s total power usage metric! So that “never” statment needs to be qualified.
Yes an Exaflop system could be constructed using CPU cores only, but at the cost of how many mega/giga Watts to run the thing!
Very bad on the research/fact checking part, and it’s the power budget that will make GPUs the better choice for an exascale level of computing without needing a didicated Nuke Plant just to feed the juce to a CPU only exaflop rated computer.
So that “never” needs to be qualified as never economically done with respect to a CPU only based exascale system, without the help of some dedicated GPU/Other accelerators.
How about hardware acceleration using FPGAs?
How FPGAs Can Take On GPUs And Knights Landing
https://www.nextplatform.com/2016/03/17/fpgas-can-take-gpus-knights-landing/
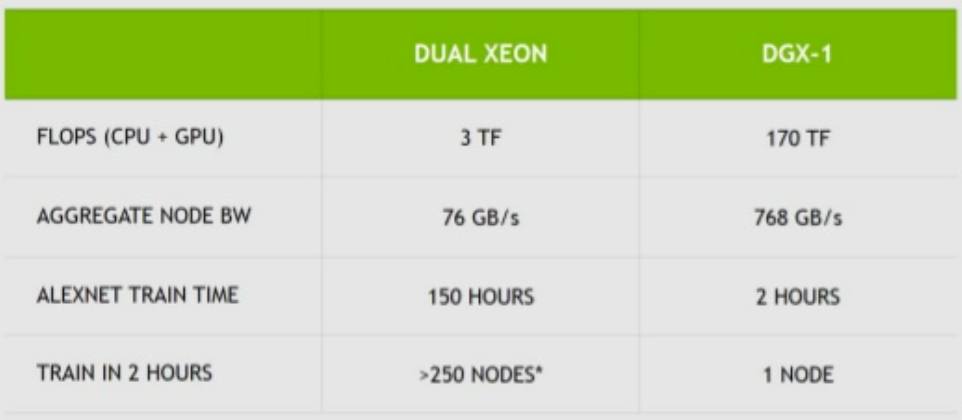
I loathe that NVIDIA comparison chart. Dig deeper. The 3 TFLOPS on the dual Xeon is single precision (32 bit). The 170 “TFLOPS” for the 8x NVIDIA GPUs in the DGX-1 is half precision (16 bit). Apples to raisins comparison.
That’s standard NVIDIA marketing for you.
Just what they wanted to have happen – show the slide without the accompanying disclaimer that the 170 TFLOPS is half precision. Perpetuates the lie.
From here:
http://www.nvidia.com/object/tesla-p100.html
P100 is 10.6 SP TFLOPS * 8 P100’s in the DGX-1 = 84.8 SP TFLOPS.
Nothing to sneeze at, but a far cry from the misleading 170 TFLOPS in the chart.
Verification: from the same NVIDIA web page:
P100 is 21.2 HalfP TFLOPS * 8 P100’s in the DGX-1 = 169.6 HalfP TFLOPS.