

If there is any phrase that describes Twitter, both from the infrastructure and end user points of view, it is real time. The social giant has been tasked with not only delivering and serving up instant updates, search results, recommendations, and further, real-time classifications that generate other services, including the trending topics, but doing so with billions of events as they arrive.
For over three years, Twitter engineering teams relied on the real-time stream processing engine, Storm, for these capabilities. And in that span of time, the popularity of Storm has found its way into a number of other settings after Twitter took the project over from its creators at Backtype and arguably, set the stage for its enterprise expansion. Storm is now the real-time processing engine behind key operations at a number of web companies, including Baidu, Alibaba, and large sites including the Weather Channel, Spotify, and Groupon.
Although it has been proven at scale, Twitter is beginning to outgrow the performance bounds of Storm and has developed a new approach to real-time stream processing via Heron, which is API compatible with Storm, but can get around some of the major hurdles Twitter engineers have encountered performance-wise.
To be fair, however, as Karthik Ramasamy, who leads the real-time analytics engineering team at Twitter says, Storm has been an incredible tool. It can analyze data the moment it is produced, provide multiple options for message passing, is horizontally scalable (a big benefit, he notes) and can abstract a lot of the plumbing. But with the increasing volume of instant processing requirements grow, some of the defining features of Storm, including its native scheduler and resource management feature (Nimbus) in particular, become bottlenecks. While these might not be enough to make companies like WebMD or the Weather Channel reroute their engineering operations, Twitter has some unique conditions—scale and volume being the two defining ones.
What’s interesting about the Nimbus element in Storm is that while it is utterly essential, it is serving many purposes at once, although not thoroughly enough. And as we know, if there is a single point of function, there’s a single point of failure. More practically, it is a scheduler, but one that doesn’t actually enforce any resource reservations. It’s a monitoring tool, but that adds overhead just for it to watch the various topologies and nodes. In other words, it lacks robustness for something that eats up so much resource-wise of the real-time processes—all of these feed the need for a better tool, explains Ramasamy.
There are other issues, including the way the Storm worker nodes are scheduled, difficulties with debugging given the way the threads and dataflows are split, and further, tuning for performance was also harder than it should be. With Storm, Ramasamy says, tuning was often an ad-hoc and manual process and it might take a few weeks to get a new job into production, even without the fact that there were so many different libraries and languages to manage—all of this leads to a condition that is unacceptable for the high-throughput, real-time fed world of Twitter. The impacts of the Storm limitations extend across multiple areas; from reliability, performance, efficiency, and manageability.
With this in mind, the Twitter team faced two decisions. Either keep Storm and undertake some extensive rewriting or use other existing open source solutions, even though Ramasamy says this option would mean API compatibility problems, a long migration process, and besides, from the range of options they looked at, there were either issues of working t scale or even if Twitter scale could be achieved the performance wasn’t there.

So hence the creation of Heron. The goals were quite simple—and all build out from the problems of Storm at scale. These goal include first and foremost, API compatibility with Storm, the use of more mainstream languages (getting away from the Clojure and language mix problem in favor of simply C++, Java and Python) more efficient batch process handling and task assignment (as well as task isolation) and of course, built in features designed for Twitter-specific efficiency goals.
Here’s what interesting about Heron. After so many problems with the scheduler, Twitter started to wonder whether or not a scheduler was actually necessary, especially since container-based approaches have matured since Storm came onto the Twitter scene a few years ago? They piggybacked on the Yarn and Zookeeper tools and use containers with Mesos and an open source framework called Aurora at the core to enforce the rules and get around the scheduler issues entirely. Although Ramasamy did not give numbers for the performance and efficient improvement, he did highlight the streamlined process for how jobs are allocated and can run instantly instead of passing through all the Zookeeper and other hops.
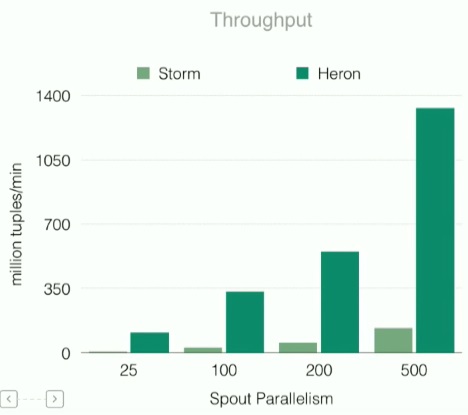 In benchmarks using the word count topology, which is one of the most challenging metrics and processes for a real-time streaming engine given the demands on data movement capabilities, Heron’s performance was quite superior. As seen in the graphic to the right, for process-once message passing, Heron far outpaced Storm. And for more complex processing tasks on the same metric (processing more than once) the performance increased further and latency was driven down dramatically as well. Further, there was a 2X-3X reduction of CPU usage (per core).
In benchmarks using the word count topology, which is one of the most challenging metrics and processes for a real-time streaming engine given the demands on data movement capabilities, Heron’s performance was quite superior. As seen in the graphic to the right, for process-once message passing, Heron far outpaced Storm. And for more complex processing tasks on the same metric (processing more than once) the performance increased further and latency was driven down dramatically as well. Further, there was a 2X-3X reduction of CPU usage (per core).
“Officially we have decommissioned Storm, we were running the largest cluster,” Ramasamy says. But now that they are in production with Heron, they are processing hundreds of topologies, billions of messages, and all in the hundreds of terabytes range. This has led to a 3X reduction in overall resource utilization, he notes, while capturing far greater performance overall.

A Hackathon To Battle The Coronavirus Pandemic
Public-private partnerships are common when responding to national or international crises and the current coronavirus pandemic that is expanding around the globe is no different. The tech industry is in the middle of it, with vendors donating millions of dollars to various private and non-profit organizations and governmental agencies, as …

One Software Container To Enclose Them All
Two years ago, the CoreOS distribution of Linux was created by two guys literally working out of a garage who wanted to make software containers the key feature, rather than an add-on, to a Linux distribution for servers. Today, the company’s appc container format and rkt implementation of that container, …
I don’t really understand how the Storm scheduler was such a big problem, but in the end they just dumped the scheduler altogether. Why not just stick with Storm and not use its scheduler?
Nimbus was a core part of the entire base–all processes were tied to this multi-language way of handing the streams (and threading/provisioning) and as he said, to just nix the scheduler wasn’t possible because they’d be looking at a full rewrite anyway.