

There are many different kinds of scale that system architects are wrestling with, and over the five decades of the modern computer business, a number of techniques have been employed, often concurrently in the same system, to try to goose the overall performance of machinery over time. Some of the greatest minds in computer science have noodled this issues, and either built experimental systems to test out their ideas or provided the inspiration for others to do so.
The saying that those who do not remember the past are condemned to repeat it, from philosopher and essayist George Santayana, does not have an inverse corollary as far as we are aware; history does tend to move in cycles as well as lines, and because of the work that so many people do, a certain amount of repetition and reinvention seems inevitable. What we know about the history of the computer business is that those who do not remember the past don’t realize how many shoulders all innovation rests upon.
We would add that it is important for the computer industry to make bold predictions and then check back in some years hence to see how the best minds of one time forecast what computing the rest of us would be using in another. Doing so teaches us a bit of history, which is always fun, as well as humility, which is another vital trait because there is nothing harder to predict than the confluence of technology, money, and human behavior. Each has its own trajectories as well as triumphs and disappointments.
We do not claim to have exhaustive knowledge of the research that has been done in scale up and scale out computing over the past several decades, but there are some important bits of thought experiment and research that we do know about, and as for the rest, we are counting on you to steer us towards the interesting work that we are not aware of that has shaped the evolution of computing at scale as we know it. The idea, of course, is to not just look at history, but to talk to the experts of this time about what the next decade or two might hold in the datacenter. But more than anything else, the idea here is to have some fun, engage our minds, and talk about the possible futures that might have been and the ones that might be.
To get the ball rolling on the future of scale, we think it is fitting to start with a paper and set of lectures by Jim Gray, a computer veteran who cut his teeth at Bell Labs and the University of California at Berkeley and worked at IBM, Tandem Computers, Digital Equipment Corp, and Microsoft Research. Among many other things, Gray worked on IBM’s System R project, the first relational database with a SQL interface, and it is he who came up with the ACID test – Atomicity, Consistency, Isolation, Durability – that describes the innate properties of transaction processing systems. Gray didn’t just work on database technologies, but also thought about the future of systems (as if the two could be separated), and while at Digital he worked on a paper with colleagues that was tweaked in 1992 and revised again in 1994, when it was eventually published as Super-Servers: Commodity Computer Clusters Pose a Software Challenge. There is an accompanying presentation related to the paper, which Microsoft Research hosts at this link.
There are a number of interesting things about this bit of prognostication by Gray, among them the fact that the old networking stacks from proprietary system makers like IBM and DEC were just starting to give way to the open protocols of the Internet while at the same time that Unix had become firmly entrenched in the datacenter and Windows NT was starting to make some headway in the glass house, too. Gray correctly saw that Windows and some POSIX compliant operating system – perhaps even Windows with POSIX layers – could become the default platform. What no one expected at the time was that Linux would be that platform and the entire systems industry would get behind it. The HPC community embraced Linux in the late 1990s, thanks to its openness and portability across platforms and because of the rise of Beowulf-style clusters for sharing simulation and modeling workloads across networked machines, and almost all HPC machines sold in the past fifteen years have run Linux. All of the hyperscalers and most of the cloud builders today deploy on Linux – with the exception of Microsoft, of course – and a very large portion of the high end, scale out workloads in the enterprise run on Linux, too.
What made this paper by Gray memorable in our minds is the phrase “smoking hairy golfballs” to describe the processors of the future (as seen from the 1994 vantage point). This is not a phrase that Gray coined, but rather was used way back in 1985 by chip designer Frank Worrell from LSI Logic, but Gray made it famous. The way that Gray envisioned the future, we would have a basic building block for compute, storage, and networking, which he called a 4B machine, which might end up as a high-end workstation on our desktops, and that Super Servers, called 4T machines, would be clusters of these machines lashed together and sharing work to feed applications and data to the 4B machines. By 4B machine, Gray meant it would have a processor with around a billion instructions per second of compute, a billion bytes of DRAM memory, a billion bytes per second of I/O bandwidth, and a billion bits per second of communications bandwidth.
“To minimize memory latency these 4B machines will likely be smoking hairy golf balls. The processor will be one large chip wrapped in a memory package about the size of a golf ball. The surface of the golf ball will be hot and hairy: hot because of the heat dissipation, and hairy because the machine will need many wires to connect it to the outside world.”
The interesting bit for us is Gray’s description of the 4T Super Server and his contention that fast clients would require faster servers. A few years after this paper was released, Gray refined his terms a bit, referring to that basic 4B element as a “cyberbrick” and the 4T Super Server was a cluster of such machines running a homogenous software stack (and given that he worked at Microsoft, assumed to be Windows NT) and providing much of the look and feel of cloudy capacity today, minus the virtualization. (Bill Laing, corporate vice president of the Server and Cloud Division at Microsoft, was one of the co-authors of the internal Super Server paper from Digital along with Gray, by the way.)
“Some believe that the 4B machines spell the end of machines costing much more than $10,000. I have a different model. I believe that the proliferation of inexpensive computers will increase the need for super-servers. Billions of clients mean millions of servers.”
This has certainly been proven true over the past two decades, although the Moore’s Law expansion of capacity inside a server has kept the server count lower than it might otherwise have been.
Here is the image of the 4T Super Server that Gray put out a few years after the 1994 paper was released:
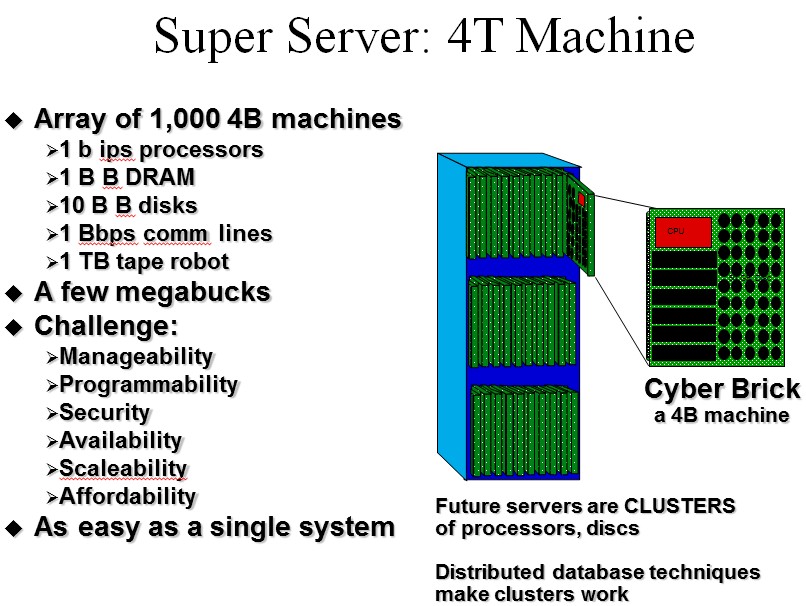
In the original paper and for the next several years, Gray assumed that disk drives would continue to shrink in their form factors, much as they had in the past, and by the time a 4T machine was in the field, he assumed that 1-inch disk drives would be common and commodities. He went even further and said that a cyberbrick might have an array of 10 by 10 of these drives mounted on the same motherboard as the CPU and DRAM, providing on the order of 100 GB of capacity. The Super Server would have tape libraries with robots for what we today call cold storage – things you store but rarely, if ever, access again.
If you squint your eyes a little bit, you can see Open Compute hardware like Microsoft’s own Open Cloud Server and earlier cluster designs from the likes of Google in the vision that Gray had back in 1994 – many years before the rack server came to the datacenter, and many more still before blade and modular machines like the Open Cloud Server design became normal. But Gray threw down the gauntlet, way back then, challenging the industry to build this kind of 4T Super System he was dreaming of:
“Anyone with software and systems expertise can enter the cluster race. The goal in this race is to build a 2000-processor 4T machine in the year 2000. You have to build the software to make the machine a super-server for data and applications – this is primarily a software project. The super-server software should offer good application development tools – it should be as easy to program as a single node. The 4T cluster should be as manageable as a single node and should offer good data and application security. Remote clients should be able to access applications running on the server via standard protocols. The server should be built of commodity components and be scalable to thousands of processors. The software should be fault-tolerant so that the server or its remote clone can offer services with very high availability.”
Google placed its big order for custom servers – a whopping 1,680 machines at a time when it only had 112 servers running its search engine – in the summer of 1999. Here is what one rack of the so-called Corkboard system, which is on display at the National Museum of American History, from Google looked like:

The servers that Google commissioned King Star Computer of Santa Clara, California to build were indeed comprised of desktop components. In this case, Google put four nodes on a corkboard shelf in the rack (hence the nickname of the system), each one based on an Intel Pentium II processor with 256 GB of main memory and two 22 GB IBM DeskStar disk drives. The networking on each node was 100 Mb/sec Ethernet, which was standard at the time. Each rack had twenty shelves, for a total of 80 nodes, and Google ordered 21 racks to get to 1,680 nodes in total – a factor of 15X over what it had in its datacenter at the time. The company now, of course, has well over 1 million servers and probably closer to 2 million, and it has invented much of the software stack that Gray dreamed of running across clusters, parallelizing workloads and serving billions of clients.
When Jim Gray was lost at sea off the coast of San Francisco in January 2007, the computer science world lost a true visionary, one that we needed to keep pushing us forward. We will continue to explore these ideas in this series of articles. Let us know what prescient research papers you think addressed the issues of scale ahead of their time.




Be the first to comment